如何在本地运行您的(无审查的)LLM
我们拥有专有的LLM以及开源的LLM,两者都表现出色。例如,撰写本文时聊天机器人的LLM的现状如下。
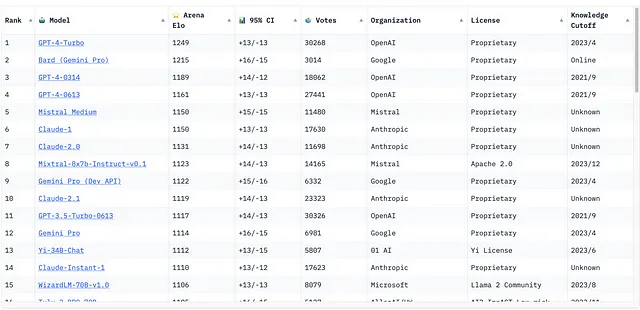
如您所见,来自法国公司Mistral的Mixtral 8x7b在性能方面与专有机型非常接近,尽管OpenAI的首席执行官Sam Altman对此类进展非常怀疑。这使得我们潜在的AI整合不会永远与OpenAI绑定,从而摆脱了对Sam Altman的任意支配。
在培训基础模型方面,与我们竞争是完全没有希望的。- Sam Altman
The Mixtral 8x7b使用开源Apache 2.0许可证授权,这与Llama不同,允许您在您希望的任何地方部署该模型并用于商业项目。
请等一下,还有更多的内容...
所有的开源模型都经过审查,这意味着训练它们的公司根据自己认为的安全标准添加了一层保护(是的,调整)。
幸运的是,我们有可能“越狱”这些型号并充分发挥它们的潜力(在您自己的风险和责任下)。已经有像Eric Hartford这样的先驱者在这个领域取得了成功。基本上,他通过对现有的Mixtral 8x7b进行微调,去除了其中的审查和偏见,创建了一个称为海豚-mixtral-8x7b的新型号。
您可以在本地运行它…
这些模型的不太令人愉快的方面是它们需要非常强大的机器以较慢的速度进行推理。在编写本文时,我使用的是一台拥有32GB内存的MacBook M1 Pro,我无法运行dolphin-mixtral-8x7b,因为它至少需要64GB内存,最终我运行了llama2-uncensored:7b——Llama 2中另一个需要较少内存(并且质量较低)的未审查模型,但运行步骤本质上是相同的。
- 下载 Ollama 适用于您的系统。与其他工具不同,我发现它非常易于使用。对于 Mac/Linux 系统,它被原生支持,但对于 Windows 系统,您需要通过 WSL 安装它。
- 运行 ollama serve
3. 运行 ollama run dolphin-mixtral:latest(应该下载 26GB)
现在您可以在终端中开始提问问题了。
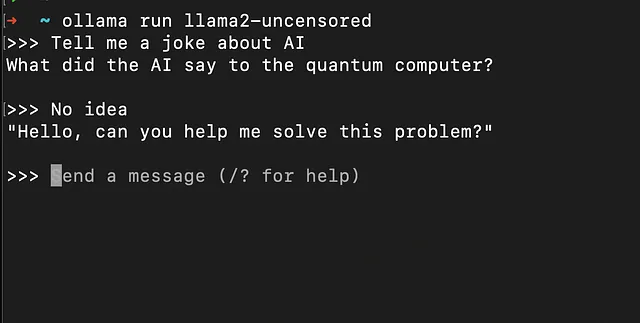
Ollama公开了REST APIs,因此您也可以调用APIs来获取您的提示信息:
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama2-uncensored",
"prompt":"Tell me a joke about AI."
}'
为什么我需要这些?
正如我之前所说,您可以为项目创建出色的集成。本地运行意味着您可以在服务器上操作它,并构建一个可靠的应用程序,而不依赖于不断变化和波动的OpenAI的API。
您还可以微调这些模型以满足您的特定需求。这需要大量的GPU计算能力,但幸运的是,您不需要购买它们;您可以使用HuggingFace的AutoTrain,或者从Replicate租用GPU进行快速推断。
跟随我在X上,继续记录我在技术和人工智能方面的经历,以及我在构建以人工智能为驱动的产品的旅程。