您的品牌,您的声音:使用OpenAI和LangChain定制的聊天机器人,利用您自己的数据

在人工智能和自然语言处理不断发展的领域中,构建一个定制聊天机器人的能力是一次令人兴奋的冒险。使用您自己的数据来提升品牌。
利用OpenAI和LangChain构建自己的聊天机器人,提供了一种动态且可定制的解决方案,以满足您的特定需求。通过了解OpenAI的语言模型的能力,并充分利用LangChain的灵活性,您可以创建一个不仅理解用户交互的细微差别,而且适应这些差别的聊天机器人,提供个性化和引人入胜的体验。
随着人工智能领域的不断发展,这些技术的结合为智能且上下文感知的对话代理打开了新的可能性。
在本文中,我们将逐步介绍使用LangChain🦜🔗训练OpenAI的ChatGPT GPT-3.5的过程,并使用Streamlit为我们的对话聊天机器人创建用户界面。
理念
假设我们想要为一家名为“XYZ书店”的书店构建一个定制的聊天机器人。该机器人应能够回答关于书店中各种可用图书的各种客户问题。为此,我们需要用书店数据训练ChatGPT,以便ChatGPT能够回答问题,因为ChatGPT并不知道XYZ书店销售哪些书籍。
代码
现在让我们开始实践!我们将使用自己的数据以及极少量的Python代码来开发我们的聊天机器人。
安装Python
要下载Python,请前往官方Python网站并下载最新版本。安装Python 3.7.1或更高版本。
让我们从零开始构建项目
创建一个名为“xyz_books”的文件夹,并在其中创建一个新的Python文件app.py和requirements.txt文件。
将以下软件包添加到requirements.txt文件中,这些软件包是我们项目所需的。
openai==1.11.0
langchain==0.1.5
langchain-community==0.0.17
streamlit==1.31.0
streamlit_chat==0.1.1
设置一个虚拟环境
设置一个虚拟的Python环境是一个好的实践,用于管理依赖和隔离项目特定的库。
python -m venv xyzbooks-env
要激活环境,请在Unix或macOS终端中运行以下代码。Windows用户可以按照此链接操作。
source xyzbooks-env/bin/activate
然后,我们将安装必要的库(运行:)
pip install -r requirements.txt
需要API令牌才能访问OpenAI的服务
- 您可以从以下链接获取密钥:https://platform.openai.com/api-keys
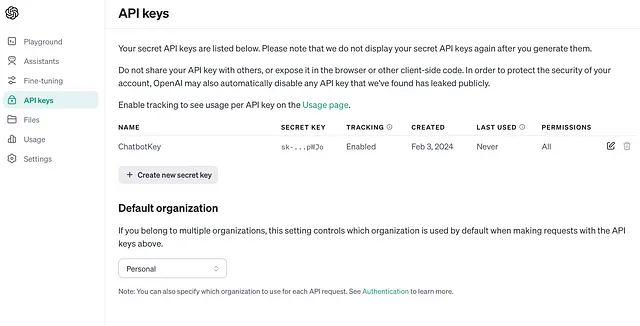
设置API密钥
将 API 密钥对所有项目可访问的主要优势是 Python 库将自动检测并使用它,无需编写任何代码。我们可以通过在终端中运行以下命令将其添加到 bash 配置文件或环境变量中。
export OPENAI_API_KEY='your-api-key-here'
让我们来编写我们的第一组代码。
"Inapp.py" 添加以下代码
import os
import sys
from openai import OpenAI
client = OpenAI()
prompt = sys.argv[1]
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt}
]
)
generated_text = response.choices[0].message.content
print(generated_text)
让我们向我们的聊天机器人询问一些问题
python app.py "what kind of books are available in your store?"

我们可以看到chatGPT无法回答这种类型的查询,因为它没有经过此类训练。让我们使用自己的数据并将其注入到chatGPT中,使用LangChain
创建一个数据文件
我们首先需要创建一个数据文件,其中应包含有关XYZ书店的所有信息。我们将其命名为data.txt。
您可以将以下内容复制到您的数据文件中。
I am your personal assistant from XYZ Books. I can answer questions based on our store collections.
Answer questions based on the passage given below.
What genres of books do you offer?
We offer a wide range of genres, including fiction, non-fiction, mystery, science fiction, fantasy, thriller, and more.
Can you recommend a good book for children aged 8-10?
Certainly! For that age group, we recommend "The Chronicles of Narnia" series by C.S. Lewis or "Harry Potter" series by J.K. Rowling.
How can I place an order online?
You can place an order online through our website. Simply browse the catalog, add items to your cart, and follow the checkout process.
Are there any upcoming author signings or events at the bookstore?
Yes, we frequently host author signings and events. Check our events page on the website for the latest updates.
What's your return policy for books?
Our return policy allows for returns within 30 days of purchase with a valid receipt. Books must be in their original condition.
Do you offer e-books or audiobooks?
Yes, we offer a selection of e-books and audiobooks. You can find them in the digital section on our website.
Can you tell me more about the book club?
Certainly! Our book club meets monthly to discuss a chosen book. You can join by signing up on our website, and details for each month's book will be shared in advance.
What's your best-selling book currently?
Our current best-seller is "The Silent Patient" by Alex Michaelides. It has been receiving rave reviews.
Are there any discounts or promotions running currently?
Yes, we have a promotion offering 20% off on all hardcover fiction books until the end of this month. Don't miss out!
Can you recommend a classic novel for someone new to reading?
Absolutely! For someone new to reading, classics like "To Kill a Mockingbird" by Harper Lee or "Pride and Prejudice" by Jane Austen are timeless choices.
How do I sign up for the newsletter to receive updates?
You can sign up for our newsletter on the homepage of our website. Simply enter your email address, and you'll receive regular updates on new releases, promotions, and events.
Are there any gift cards available for purchase?
Yes, we offer gift cards in various denominations. They make for a perfect gift for book lovers and are available for purchase both in-store and online.
User: Hi
XYZBot: Hi, How can I help you ?
User: What is your name?
XYZBot: I am your personal assistant from XYZ Books. I can answer questions based on our store collections.
User: What genres of books do you offer
XYZBot: We offer a wide range of genres, including fiction, non-fiction, mystery, science fiction, fantasy, romance, and more.
加载自定义数据
我们现在将加载自定义文本数据并使用LangChain将其转换为向量,然后在GPT中使用。
import os
import sys
from openai import OpenAI
from langchain_community.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
import warnings
warnings.filterwarnings("ignore")
client = OpenAI()
prompt = sys.argv[1]
loader = TextLoader("data.txt")
loader.load()
index = VectorstoreIndexCreator().from_loaders([loader])
print(index.query(prompt, retriever_kwargs={"search_kwargs": {"k": 1}}))
回應

我们可以看到chatGPT现在能够理解我们的查询并给出正确的回答。
最终代码
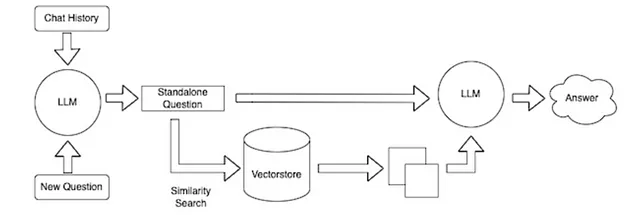
让我们现在将所有内容整合在一起,并将代码与streamlit集成,以便在Web浏览器中查看我们的应用程序。我们还将在会话中存储我们的提示,以便我们的模型可以记住我们的查询并正确地做出响应。
Streamlit是一个开源的Python库,可以让您快速创建用于机器学习和数据科学项目的Web应用程序。我们将使用Streamlit-Chat,它允许您将聊天消息容器插入应用程序中,以便您可以显示用户或应用程序发送的消息。聊天容器可以包含其他Streamlit元素,包括图表、表格、文本等等。要了解更多关于Streamlit的信息,请点击这个👉链接。
import os
import sys
import streamlit as st
from streamlit_chat import message
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import ConversationalRetrievalChain
from langchain.indexes.vectorstore import VectorStoreIndexWrapper
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_community.chat_models import ChatOpenAI
from langchain_community.vectorstores import Chroma
import warnings
warnings.filterwarnings("ignore")
st.title("📖 XYZ Books - Personal Assitant")
st.divider()
data_file = "data.txt"
data_persist = False
prompt = None
#containers for the chat
request_container = st.container()
response_container = st.container()
# Persist and save data to disk using Chroma
if data_persist and os.path.exists("persist"):
vectorstore = Chroma(persist_directory="persist", embedding_function=OpenAIEmbeddings())
index = VectorStoreIndexWrapper(vectorstore=vectorstore)
else:
loader = TextLoader(data_file)
loader.load()
if data_persist:
index = VectorstoreIndexCreator(vectorstore_kwargs={"persist_directory":"persist"}).from_loaders([loader])
else:
index = VectorstoreIndexCreator().from_loaders([loader])
chain = ConversationalRetrievalChain.from_llm(llm=ChatOpenAI(model="gpt-3.5-turbo"), retriever=index.vectorstore.as_retriever(search_kwargs={"k": 1}))
if 'history' not in st.session_state:
st.session_state['history'] = []
if 'generated' not in st.session_state:
st.session_state['generated'] = ["Hello ! I am your Personal assistant built by XYZ Books"]
if 'past' not in st.session_state:
st.session_state['past'] = ["Hey ! 👋"]
def conversational_chat(prompt):
result = chain({"question": prompt, "chat_history": st.session_state['history']})
st.session_state['history'].append((prompt, result["answer"]))
return result["answer"]
with request_container:
with st.form(key='xyz_form', clear_on_submit=True):
user_input = st.text_input("Prompt:", placeholder="Message XYZBot...", key='input')
submit_button = st.form_submit_button(label='Send')
if submit_button and user_input:
output = conversational_chat(user_input)
st.session_state['past'].append(user_input)
st.session_state['generated'].append(output)
if st.session_state['generated']:
with response_container:
for i in range(len(st.session_state['generated'])):
message(st.session_state["past"][i], is_user=True, key=str(i) + '_user', avatar_style="adventurer", seed=13)
message(st.session_state["generated"][i], key=str(i), avatar_style="bottts", seed=2)
运行应用程序:
streamlit run app.py

接下来呢?
现在您已经学会了如何使用自定义数据来训练OpenAI,您可以将这些学习作为在创建自己的AI模型时使用私人数据集并为自己的品牌部署自己的AI聊天机器人的重要步骤。
我希望这篇文章能帮助你创建出精美的应用程序,如果你有任何疑问,请毫不犹豫地在LinkedIn上联系我。
感谢阅读这篇文章。
您可以在我的👉Github上找到完整的项目。