为什么向量空间是机器学习的未来
这篇文章是我对Transformer的注意机制研究的精华总结。我不仅想要了解注意机制的运作方式,还想弄清楚其背后的原理和在机器学习广阔领域中的重要性。哎呀,我可真是有口福啊!
理解注意力机制
在神经网络中,注意力的概念本质上是对人类集中注意力能力的模拟。就像一个人可以在拥挤的房间里专注于特定的声音一样,注意力机制允许人工智能模型从大量的数据中关注相关的信息。这种能力不仅仅是技术上的改进,它是机器处理信息的一种范式转变。
在这个机制的核心是向量空间的概念。为了理解这些空间的重要性,让我们首先揭秘它们是什么。
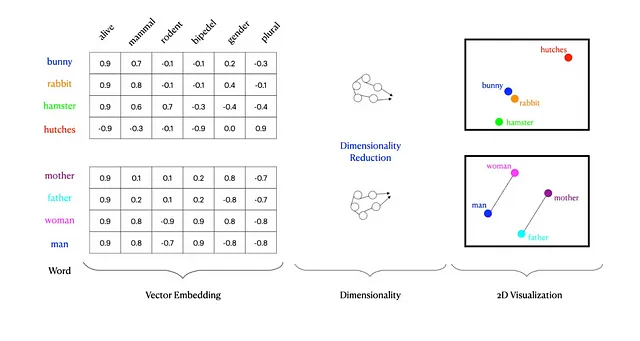
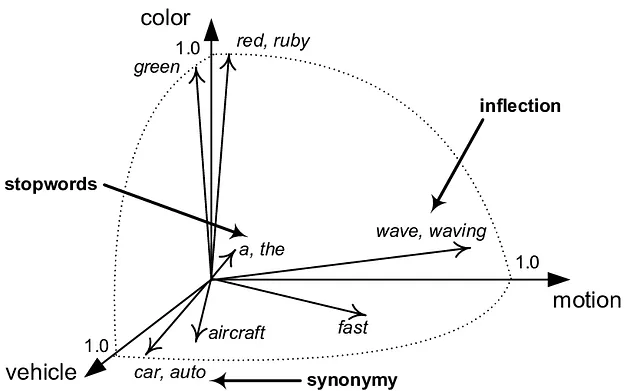
在机器学习领域中,向量空间实际上是一个数学概念,其中每个点代表一条数据。这些空间使我们能够以机器可计算的方式量化和分析数据点之间的关系。
当我们谈论将数据投射到这些空间时,我们指的是将原始数据转化成突显其固有模式和关系的形式。这个过程就像将一本复杂的书籍翻译成一个孩子能理解的语言一样。变压器注意机制利用这些投射,使模型能够区分出对于当前任务最相关的数据点(或词语,根据我们的类比)。
这种方法的亮点在于其简单性和有效性。通过将向量空间作为画布,注意机制描绘出数据的画面,突出显示其最关键的元素。这个过程不仅提高了模型的准确性,还提高了模型的效率,因为它不再需要以相同的权重筛选每一个数据片段。
令向量空间更加令人着迷的是其潜在的可扩展性。
在我理解了注意力机制之后,我意识到
我们可以构建一个通用的向量空间,一个广阔的、维度丰富的空间,可以表示和关联人类知识谱域中的每一个微妙的数据。
向量空間:知識的無限圖書館
在我对变压器注意力机制的探索中,一个关键时刻是意识到向量空间是这些模型的支撑结构。这些空间不仅仅是数学构造;它们是数据的精华的提炼和理解的领域。正是在这些空间中,注意力机制的真正力量展现出来,揭示出了模拟认知过程的细微差别和理解的能力。
为了说明数据如何投影到向量空间中,考虑以下代码:
input_dim = 512 # Dimension of the input vector
model_dim = 64 # Dimension for the query/key/value vectors
# Initialize a linear transformation
random_linear_projection = nn.Linear(input_dim, model_dim * 3, bias=False)
# Project the input vector into a higher-dimensional space
projected_vector = random_linear_projection(input_vector)
# Split the projected vector into query, key, and value vectors
query, key, value = projected_vector.chunk(3, dim=-1)
这段代码不仅仅是对数字进行操作,它封装了将数据投影到向量空间中的实质,这样模型就可以对其进行分析和解释。通过将投影向量分成查询、键和值,我们实际上是为数据准备在多个子空间中进行探索,每个子空间都提供了对数据的独特视角。
子空间:多元化视角
将向量空间分为子空间,通过注意机制的帮助,是一种令人大开眼界的认识。每个子空间使模型能够专注于数据的不同特征或方面,类似于通过不同角度观察宝石的各个表面以欣赏其美丽。这种多样性的观点丰富了模型的理解能力,使其能够把握数据中的复杂关系。
考虑到重塑和转置操作是如何准备向量以进行注意力计算的:
# Reshape and transpose for multi-head attention computation
batch_size = 1
seq_length = 10
num_heads = 8
query = q.view(batch_size, seq_length, num_heads, model_dim).transpose(1, 2)
key = k.view(batch_size, seq_length, num_heads, model_dim).transpose(1, 2)
value = v.view(batch_size, seq_length, num_heads, model_dim).transpose(1, 2)
通过这些操作,注意机制的每个“头部”可以独立分析数据,提供一个综合性的理解,这是单一视角无法达到的。这就是注意机制真正的巧妙之处,使得模型能够辨别大规模数据集中的微妙细微差别和模式。
个人领悟和启示
我的对向量空间和注意力机制架构的探索带来了一个深刻的认识:构建一个集中式的向量空间,模型可以普遍地从所有可用数据中学习的潜力。
想象一下这样一个系统的潜力,其中模型的输入就是注意机制的输出。比如:
def forward(self, cursor):
# Simulate getting input vector from a high-dimensional vector space
return vector_space_attention(cursor)
或者,为了这一点要牢牢系住你的帽子,一个巨大的向量空间被推广到所有人类知识和文献。一种新的架构出现了,在这种架构中,我们不再训练模型,而是通过这个空间进行推理。我承认这有点像科幻,但通用人工智能将需要这样的结构。
个人反思
回顾我通过这项研究所学到的,我对Google研究人员在《Attention Is All You Need》论文背后的智慧感到敬畏。
一开始我心里想
初始化三个随机矩阵并将它们与相同的输入进行相乘,在任何情况下都不可能具有任何意义。
但是天才的想法是:
- 矩阵仅在开始时是随机的。这种随机性有助于打破学习过程中的对称性,确保模型能学习到多样化的特征,不陷入重复的模式中。
- 它们是学习参数,意味着它们会根据损失函数的梯度进行更新。这个更新过程通过反向传播和优化算法来实现,逐渐调整这些矩阵。随着时间的推移,这些矩阵从随机初始化演变为高度结构化的变换器,嵌入了对数据内部关系的复杂理解。
邀请未来
能够访问、学习和贡献于人类知识总和的人工智能的潜力不再是科幻,而是逼近的现实。从关注机制和向量空间的基础概念到旨在利用这些概念推动人工智能发展的雄心勃勃的项目,只是对等待着我们的巨大潜力的一瞥。
感谢阅读,请不要忘记关注以获取更多精彩文章。