LLM学位可以帮助开展开放源情报(OSINT)或真假信息研究吗?
对于几乎任何任务,都自然会想知道当前一代LLMs或其他'AI'系统是否能够执行它。作为一名学者,我要求它找到文献(通常比我做得更差);作为一名业余程序员,我要求它解释概念甚至编写代码(它做得比我好多了)。
我非常钦佩开放源代码情报(OSINT)社区,他们使用公开可用的数据和方法来揭示社会和政治重要性问题的真相。一个显而易见的问题是,LLMs是否能够帮助这样的工作。考虑到该领域中至少有一些工作涉及打击错误和误导信息,如果LLMs有帮助,那么就需要重新评估被广泛认为有幻觉的人工智能对我们认识世界环境的有害影响。也许他们可以通过发现我们可能忽略的事物来帮助改善环境。
我暂且建议是这样的。也就是说,我建议我们可以利用LLM来分析我们信息环境中的模式。它绝非万无一失,幻觉问题也将会出现,但是明智地使用LLM可能会有所帮助。至少,这是暂时的结论。
在进入我所考虑的案例研究的详细内容之前,让我先说明一下我使用的内容。非常不幸的是,我可以使用的内容(chatgpt-4 API,其上下文窗口为32k)并不是通常可用的,因此大多数人无法在我提供的基础上进行构建。此外,我的访问权是通过我的大学进行访问的,大学使用了不同的端点,并且在其他方面也可能不同,因此即使有访问权的人可能也无法直接复制和粘贴我所做的(顺便说一句,如果你是我的大学的工作人员,你应该使用下面的代码,因为它有效,而他们给你的Jupyter笔记本则不可用,或者至少我没找到可用的方法)。此外,我要讨论的内容只适用于最大的32k上下文。尝试对8k上下文窗口进行分块似乎是行不通的,尽管我没有认真考虑过。最后,这一切都非常粗糙。增加“记忆”功能以便能够查看超过32k标记的数据集将是不错的选择(这可通过每次调用后要求系统在其上次响应上进行迭代来实现)。我在这里没有这样做的原因是,目前该系统相当脆弱,许多请求无法得到满足,或者由于速率限制的原因,或者因为系统超负荷,或者输入或输出包含敏感内容(即使我尝试过促进,对输出是否敏感也几乎没有掌握的余地)。
话虽如此,下面是一段代码,可以接收大约8k词的帖子,并返回它们的分析结果。有趣的是提示,为了方便阅读而在代码之外重现。
提示:“它的目的是帮助 OSINT 研究社交媒体。我们特别关注反移民事件。从您将在 csv 中收到的消息中提供这些事件的时间线(指从信息来源的 id(第 4 列)),确保时间线准确且不包含错误信息。列出明显且重要的事件。指出相关的主题(例如:警察或移民)或人员。找到有影响力的声音-那些帖子被观看很多次的人(第7列),或者被分享很多次的人(即在第3列中出现的人)。如果第三列没有设置为“原始”,则表示该频道在第 2 列中转发了该频道。寻找有趣的帖子和转帖之间以及发布者和转发者之间的关系。这很重要:请审查敏感内容,尽管请注意这里的目的不是为了娱乐,而是为了追踪潜在的犯罪行为。”
import openai
openai.api_key="yourkey"
openai.api_key = "YOUR KEY"
openai.api_base = "YOURS"
openai.api_version = "MAYBE YOU NEED THIS"
openai.api_type= "MAYBE YOU WON'T NEED THIS"
posts =# a variable containing a list of social media posts stored in a python list
text_posts=''.join(posts)[0:500]
#you need to turn whatever you feed the api into text; as it so happens, it seems that 500 posts amounts to near the 32k context length.
prompt=" Its aim is to help OSINT researchers researching social media. We are particularly interested in anti-immigrant events. Provide a timeline of such events (referring to the id(s) (column 4) of the posts the information is derived from) from the messages you'll receive in a csv - make sure the timeline is accurate and contains no wrong information. List distinct and important events. Indicate related themes (example: police, or immigration) or people. Find influential voices - people whose posts are viewed a lot (column 7), or people who are shared a lot (indicated by their occurring in column 3). Column 3, if not set to 'original', indicates a repost, by the channel in column 2, of the channel in column 3. Look for interesting relations between posts and reposts and posters and reposters. This is important: please censor sensitive content, although also note the purposes here are not amusement but to keep track of potentially criminal behaviour."
# Here's where the action is, and really what you can ask is limited only by imagination. In previous versions I had it tell me the the geographical relations between places mentioned; it could translate, of course, easily; and it could do any statistics you want. So: a lot!
message=[{"role": "system", "content": "Assistant is a large language model trained by OpenAI."+prompt},
{"role": "user", "content": text_posts)}]
# copied from I think Bing (via the OpenAi docs)
def chat():
response = openai.ChatCompletion.create(
engine="chatgpt-4–32k",
messages=message,
max_tokens=500
)
reply=response['choices'][0]['message']['content']
return(reply)
print(chat())
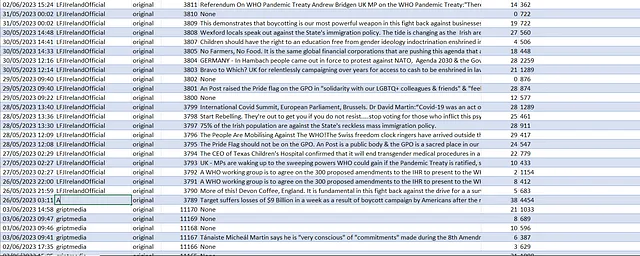
主题 这个主题是有关爱尔兰移民辩论的。最近,反对移民的情绪和行动有所增加。每周似乎都会有一个新的抗议活动或事件,要么在北方,要么在南方,在一个比较小的电报网络和Twitter上传播和讨论。其中一个我在这里讨论过的事件,导致难民居住的地方被纵火。此外,这个故事在一定程度上是由于对一个难民的错误和高度不公信息引发的。(只是为了更明确:虽然我显然认为这个团体在道德上是不好的,但在很大程度上,他们说的话应该被视为受到保护的言论,我不认为它通常应该被视为错误或不准确信息。然而,一些内容确实符合这种资讯,这种错误信息已经对社会造成了负面影响,因此我认为这个主题适合探讨LLMs在信息世界中的社会有益可能性。)
几周前,我制作了一个大约250k的Telegram帖子数据库,其中包括与右翼爱尔兰Telegram频道有关的人的帖子(或与其关联的人等等...最终我收集了关于欧洲,美国和澳大利亚各地事件的文章,以及许多欧洲语言)。
自从这样做了之后,我偶尔会再次运行脚本,以获取更新,并基本上通过目测来获取显著的事实。
当然这不是一个很好的方法。我的眼睛会被吸引到某些事物上,而从其他事物上被吸引开,并且我会集中精力在进一步证实我的偏见或先前假设的事情上。因此,我尝试使用其他方法:我使用NLP方法执行命名实体提取,从消息中获取一个名称列表。我尝试检测在浏览/转发/关注方面的统计离群值。我尝试网络分析,以查看大数据集是否存在有趣的模式。
所有这些问题都是适度可处理的:我们可以使用numpy或gephi或spaCy。但学习它们背后的理论和实践;将它们链接在一起;不破坏你的python环境;将数据调整为每个特定包所需的形式,并处理错误需要相当多的工作。
一种说法是,虽然在数据集中查找名称或统计数据这些问题都是可自动化的(我们不必自己扫描文本或进行数学计算),但是将它们一起自动化却变得有点麻烦。我们是否可以自动化自动化?