RAG v 细调:为何不融汇两者的力量!
特点 | 推测 | 微调 — 基于科技新闻架构的LLM为基础的RAG应用的3流程架构
在本文中,我们将介绍一个项目,该项目将使用像llama2 7B这样的较小模型来进行RAG,并使用类似GPT-4这样的专家来策划问答数据集,该数据集将用于微调。当我们的紧凑模型足够理解技术术语时,我们将逐渐淘汰GPT4(例如,可能需要6个月或6个微调周期)。
所以每天上午9点我们将运行ETL来提取最新的文章,对其进行转换并加载到向量数据库中。通过聊天机器人界面查询这些数据,并定期使用Q/A数据集训练LLM。
让大老板来教新手们 ;)
什么是RAG?(检索增强生成)
LLMs的知识有限,因为它们只能根据预先训练时所见的内容进行言说。RAG是一种使用指导调整的LLM来回答来自非模型记忆(技术上是模型权重)的数据的概念,而是根据提示中给出的某些上下文。由于每个提示的令牌限制,我们会提供有限且最相关的文本来给出答案。


什么是微调?
精细调整是在特定任务上对预先训练的LLM进行进一步训练和调整的过程(在我们的情况下是技术)。这涉及再次运行神经网络,但只使用特定的训练数据集来更新其权重。
微调并不是每隔一天都会进行的工作,因为它具有高计算成本,并需要数个小时才能达到最佳性能水平。虽然RAG在您有频繁的新数据点时非常有用,但由于提示标记的限制,它在给定上下文的相关性方面存在局限性。
因此,我们将利用微调技术使我们的LLM成为技术领域的专家,同时保持RAG用于回答最新文章。
技术栈:运行此项目所需的工具

让我们现在系好安全带,展示技术细节并让事情动起来吧!
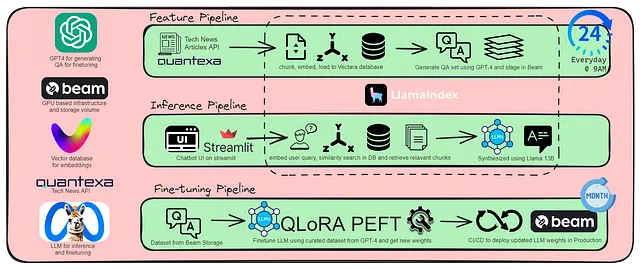
该项目涉及三条管道。
- 特性流水线: 它将每天上午9点作为调度程序运行。它包含ETL从Quantexa API抓取新闻文章,然后使用Vectara对其进行切块、嵌入和加载到向量存储器中。第二部分是使用GPT-4从每篇文章中生成5个问题和答案对,并将其保存为CSV文件到Beam存储卷上。
- 推断管道:在 Streamlit 聊天界面上,用户可以提问,这些问题将作为 Vectara 的输入,通过余弦相似度嵌入并搜索所有新闻文章中的相关块。Llama2 7B 在 Beam 上作为一个 restful API 托管以进行推断,然后调用该 API 来合成最终的回答。
- 微调流程:将此流程再次部署为 Beam 上的调度程序,以每月运行一次。它使用 PEFT LoRA 和 huggingface transformer 库对 LLM 进行微调。参数和提示器与 Alpaca 使用的相同。
特征管道应用
步骤1:创建一个名为load.py的文件——您需要从Quantex获取凭证,您可以在此处注册:https://aylien.com/news-api-signup 并获得14天的免费试用。
import requests, os, time, datetime
from dotenv import load_dotenv
load_dotenv()
#credentials for the Aylien News API
username = os.environ["AYLIEN_USERNAME"]
password = os.environ["AYLIEN_PASSWORD"]
AppID = os.environ["AYLIEN_APPID"]
def extract():
token = requests.post("https://api.aylien.com/v1/oauth/token", auth=(username, password), data={"grant_type": "password"}).json()["access_token"]
print(token)
headers = {"Authorization": "Bearer {}".format(token), "AppId":"d1ae1185"}
url = 'https://api.aylien.com/v6/news/stories?aql=industries:({{id:in.tech}}) AND language:(en) AND text: (tech, google, openai, microsoft, meta, apple, amazon) AND categories:({{taxonomy:aylien AND id:ay.appsci}}) AND sentiment.title.polarity:(negative neutral positive)&cursor=*&published_at.end=NOW&published_at.start=NOW-1DAYS/DAY'
response = requests.get(url, headers=headers)
data = response.json()
print(data)
stories = data['stories']
combined_text_list = []
for story in stories:
body = story['body']
combined_text_list.append(body)
return combined_text_list
步骤2:创建一个名为transform.py的文件 — 您需要Vectara和Beam以及OpenAI账号。我们将把嵌入文件加载到Vectara中,并将QA数据集保存在Beam存储中。
Vectara有免费版本:https://console.vectara.com/signup Beam提供首次10小时免费使用 — 应该足够,除非你尝试进行精调: https://www.beam.cloud/login OpenAI:人人皆知 ;)
import requests, os, time, datetime
from dotenv import load_dotenv
load_dotenv()
import pandas as pd
import numpy as np
import ast
from llama_index import Document
import openai
from openai import OpenAI
openai.api_key = os.environ["OPENAI_API"]
def transform(articles):
current_datetime = datetime.datetime.now()
formatted_datetime = current_datetime.strftime("%Y-%b-%d")
documents = [Document(text=t, metadata={"Article_Date": formatted_datetime}) for t in articles]
#Transform Step2: extracting questions from articles
system_prompt = """
You are an AI Based Question Generator. Given the following Article, please generate 5 questions.
Questions should be specific to the article and should be answerable from the article.
Give response in the form of list. See the example below for formatting response:
example: ["What is the name of the company?", "What is the name of the CEO?"]
Make sure that it is "" and NOT ''.
Do not write anything other than the questions wapped in [] and seperated by ,.
"""
questions_df = pd.DataFrame(columns = ['Questions', 'Answers', 'Finetuned'])
for article in articles:
client = OpenAI(api_key=os.environ["OPENAI_API"])
completion = client.chat.completions.create(
model="gpt-3.5-turbo-0125",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": article}
]
)
qns = completion.choices[0].message.content
qns = ast.literal_eval(qns)
for q in qns:
questions_df.loc[len(questions_df)] = [q, 0, 0]
return questions_df, documents
步骤3:创建一个名为load.py的文件。
import requests, os, time, datetime
from dotenv import load_dotenv
import pandas as pd
import numpy as np
load_dotenv()
from llama_index.indices import VectaraIndex
from llama_index import Document
VECTARA_CUSTOMER_ID=os.environ["VECTARA_CUSTOMER_ID"]
VECTARA_CORPUS_ID=os.environ["VECTARA_CORPUS_ID"]
VECTARA_API_KEY=os.environ["VECTARA_API_KEY"]
os.environ['OPENAI_API_KEY'] = os.environ["OPENAI_API"]
index = VectaraIndex(vectara_api_key=VECTARA_API_KEY, vectara_customer_id=VECTARA_CUSTOMER_ID, vectara_corpus_id=VECTARA_CORPUS_ID)
query_engine = index.as_query_engine()
def get_gpt_ans(question):
response = query_engine.query(question)
return response
def load(documents, df):
index.add_documents(documents)
df['Answers'] = df['Questions'].apply(lambda question: get_gpt_ans(question))
return df
第四步:最后,通过app.py创建一个调度器,将这3个函数包装起来,然后在Beam上部署和运行。
在进行部署之前,请确保已成功安装 Beam。链接:https://docs.beam.cloud/getting-started/installation
from beam import App, Volume, Runtime, Image
from load import load
import logging, datetime
from transform import transform
from extract import extract
import pandas as pd
import numpy as np
import os, time
volume_path = "./finetuning_data"
app = App(
name="FeaturePipeline",
runtime=Runtime(
cpu=2,
memory="4Gi",
image=Image(
python_version="python3.10",
python_packages="requirements.txt",
),
),
volumes=[
Volume(
name="finetuning_data",
path=volume_path,
)
],
)
@app.schedule(when="0 9 * * *")
def FeaturePipeline():
try:
articles = extract()
questions_df, documents = transform(articles)
df = load(documents, questions_df)
current_datetime = datetime.datetime.now()
csv_data = df.to_csv(index=False)
formatted_datetime = current_datetime.strftime("%Y-%b-%d %H:%M:%S")
with open(f"{volume_path}/finetune_data_{formatted_datetime}.csv", "w") as f:
f.write(csv_data)
except Exception as e:
logging.error("Error: %s", e)
print("Error: ", e)
尝试运行这个应用程序:beam run app.py: 特征管道 用于部署:beam deploy app.py: 特征管道
到目前为止,我们能够通过提取新文章并将其转化为GPT-4的嵌入和问答数据集,然后分别将它们加载到Vectara向量存储和Beam存储中来提取我们的特征或数据,并且一旦部署,它将在每天上午9点触发。
推理流水线应用程序
步骤1:将Llama2部署为推理的REST API。在一个名为llama2的独立文件夹中创建app.py,并将其设置为当前目录。使用以下代码。您需要Hugging Face的API密钥,可以在此处找到:https://huggingface.co/pricing
from beam import App, Runtime, Image, Output, Volume, VolumeType
import os
import torch
from transformers import (
GenerationConfig,
LlamaForCausalLM,
LlamaTokenizer,
)
base_model = "meta-llama/Llama-2-13b-chat-hf"
app = App(
name="llama2",
runtime=Runtime(
cpu=1,
memory="32Gi",
gpu="A10G",
image=Image(
python_packages=[
"accelerate",
"transformers",
"torch",
"sentencepiece",
"protobuf",
"bitsandbytes",
"peft"
],
),
),
volumes=[
Volume(
name="model_weights",
path="./model_weights",
volume_type=VolumeType.Persistent,
)
],
)
@app.rest_api()
def generate(**inputs):
prompt = inputs["prompt"]
tokenizer = LlamaTokenizer.from_pretrained(
base_model,
cache_dir="./model_weights",
use_auth_token=os.environ["HUGGINGFACE_API_KEY"],
)
model = LlamaForCausalLM.from_pretrained(
base_model,
torch_dtype=torch.float16,
device_map="auto",
cache_dir="./model_weights",
load_in_4bit=True,
use_auth_token=os.environ["HUGGINGFACE_API_KEY"],
)
tokenizer.bos_token_id = 1
inputs = tokenizer(prompt, return_tensors="pt")
input_ids = inputs["input_ids"].to("cuda")
generation_config = GenerationConfig(
temperature=0.1,
top_p=0.75,
top_k=40,
num_beams=4,
max_length=512,
)
with torch.no_grad():
generation_output = model.generate(
input_ids=input_ids,
generation_config=generation_config,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=128,
early_stopping=True,
)
s = generation_output.sequences[0]
decoded_output = tokenizer.decode(s, skip_special_tokens=True).strip()
print(decoded_output)
return {"answer": decoded_output}
将此部署到 Beam 平台:beam deploy app.py:generate
第二步:创建一个名为inference.py的新文件。这将使用Vecatara存储的文章上的RAG进行llama-index,并在streamlit上提供用户界面。在这里,我正在从Beam调用部署的llama2模型,一旦您准备好了部署,您可以通过在beam控制台中点击蓝色的“调用API”按钮找到API代码。
from llama_index.indices import VectaraIndex
import os, time, json, requests
from dotenv import load_dotenv
from model import call_model
load_dotenv()
VECTARA_CUSTOMER_ID=os.environ["VECTARA_CUSTOMER_ID"]
VECTARA_CORPUS_ID=os.environ["VECTARA_CORPUS_ID"]
VECTARA_API_KEY=os.environ["VECTARA_API_KEY"]
os.environ['OPENAI_API_KEY'] = os.environ["OPENAI_API"]
Beam_key = os.environ["Beam_key"]
index = VectaraIndex(vectara_api_key=VECTARA_API_KEY, vectara_customer_id=VECTARA_CUSTOMER_ID, vectara_corpus_id=VECTARA_CORPUS_ID)
url = "https://dys3w.apps.beam.cloud"
def call_model(prompt):
payload = {"prompt": prompt}
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Authorization": f"Basic {Beam_key}",
"Connection": "keep-alive",
"Content-Type": "application/json"
}
response = requests.request("POST", url,
headers=headers,
data=json.dumps(payload)
)
pattern = r'answer:(.+)'
res = response.json()
res = res['answer']
match = re.search(pattern, res, re.DOTALL)
answer_content = match.group(1).strip()
return answer_content, res
else:
return "No results found.", res
def final_response(prompt):
#first we get similar docs from the index
print("doing doc search")
docs = index.as_retriever(summary_enabled=True, similarity_top_k=3)
sim_docs = docs.retrieve(prompt)
sim_docs_text = [doc.text for doc in sim_docs]
print("got similar docs")
#now we pass our prompt + similar docs to the llm
prompt_2 = f"""
You are given the the context below. Please use that context only to answer the asked question.
context: {sim_docs_text}
question: {prompt}
answer:
"""
#now invoking the llm
output, out2 = call_model(prompt_2)
return output
#using chainlit UI
import streamlit as st
st.title('Ask me anything about Technology')
prompt = st.text_area("Enter your question here", "What is software sentiment")
if st.button('Submit'):
with st.spinner('Wait for it...'):
st.success(final_response(prompt))
保存此文件并使用以下命令运行:streamlit run inference.py
现在我们有一个带有聊天机器人的用户界面,可以与存储在向量数据库中的所有新闻数据进行交流!
优化流水线应用
要进行微调,您可能需要从Beam.cloud购买付费版本。我们将使用以下Github仓库:https://github.com/slai-labs/get-beam/tree/main/examples/finetune-llama?他们在那里创建了通用训练函数,但它使用了来自hugging face数据集包的数据。下面是您的app.py文件的更新代码,它将使用我们存储在Beam中的问答数据集。
from math import ceil
from beam import App, Runtime, Image, Volume
from helpers import get_newest_checkpoint, base_model
from training import train, load_models
from datasets import load_dataset, DatasetDict, Dataset
#from inference import call_model
import pandas as pd
import numpy as np
import os
beam_ft_data_volume = "./finetuning_data"
# The environment your code runs on
app = App(
"llama-lora",
runtime=Runtime(
cpu=4,
memory="32Gi",
gpu="A100-80",
image=Image(
python_version="python3.10",
python_packages="requirements.txt",
),
),
# Mount Volumes for fine-tuned models and cached model weights
volumes=[
Volume(name="checkpoints", path="./checkpoints"),
Volume(name="pretrained-models", path="./pretrained-models"),
Volume(name="finetuning_data", path=beam_ft_data_volume)
],
)
# Fine-tuning
@app.schedule(when="0 9 1 * *")
def train_model():
# Trained models will be saved to this path
beam_volume_path = "./checkpoints"
csv_files = [file for file in os.listdir(beam_ft_data_volume) if file.endswith(".csv")]
combined_df = pd.DataFrame()
dfs = []
for csv_file in csv_files:
file_path = os.path.join(beam_ft_data_volume, csv_file)
df = pd.read_csv(file_path)
dfs.append(df)
combined_df = pd.concat(dfs, ignore_index=True)
combined_df.reset_index(drop=True, inplace=True)
combined_df = combined_df.drop('Finetuned', axis =1)
combined_df.rename(columns={"Questions": "instruction", "Answers": "output"}, inplace=True)
combined_df['input'] = np.nan
# Load dataset -- for this example, we'll use the vicgalle/alpaca-gpt4 dataset hosted on Huggingface:
# https://huggingface.co/datasets/vicgalle/alpaca-gpt4
dataset = DatasetDict({
"train": Dataset.from_pandas(combined_df),
})
# Adjust the training loop based on the size of the dataset
samples = len(dataset["train"])
val_set_size = ceil(0.1 * samples)
train(
base_model=base_model,
val_set_size=val_set_size,
data=dataset,
output_dir=beam_volume_path,
)
部署应用程序:beam deploy app.py:train_model
总之,我们拥有一个完整的模型,可以在环境中回答问题,并且对技术术语有深入的理解,还可以通过权重帮助推理。我们最终使用了当代先进的OpenAI的GPT-4技术,使我们的小伙伴(Llama2)成为专家!
对于那些感兴趣的人,这里是Github存储库链接:https://github.com/sarmadafzalj/LLMOps-3pipelines-Batch_Ingestion-Finetuning-And-RAG_Inference
我希望你能够理解这个项目并阅读我在Medium上的第一篇文章——干杯🥂


