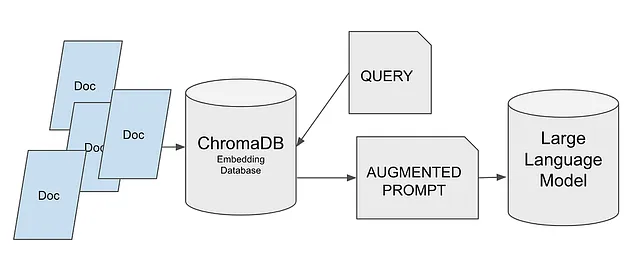
ChromaDB:一个开源向量数据库

Chroma是由Chroma公司开发的一个矢量存储/矢量数据库。与许多其他矢量存储一样,Chroma DB用于存储和检索矢量嵌入。好处是Chroma是一个免费且开源的项目。这使得世界各地的其他熟练开发者有机会提出建议并对数据库进行巨大改进,甚至可以期待在处理开源软件问题时获得快速回复,因为整个开源社区都在这里见证和解决这个问题。
让我们从Chroma DB开始
在本部分中,我们将安装Chroma并查看其提供的所有功能。首先,我们将通过pip命令安装该库。
!pip install chromadb -q
!pip install sentence-transformers -q
色度向量存储 API
这将下载Python的Chroma Vector Store API。使用这个包,我们可以执行诸如存储矢量嵌入、检索它们以及对给定的矢量嵌入进行语义搜索等所有任务。
import chromadb
from chromadb.config import Settings
client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet",
persist_directory="/content/"
))
内存数据库
我们将从创建一个持久的内存数据库开始。上面的代码将为我们创建一个。要创建一个客户端,我们需要从Chroma DB中获取Client()对象。现在要创建一个内存数据库,我们需要使用以下参数配置我们的客户端。
- chroma_db_impl = "鸭鸭DB+列式存储"
- persist_directory = “/content/” 持久目录 = "/content/"
这将创建一个内存中的DuckDB数据库,并使用parquet文件格式。我们提供存储数据的目录。在这里,我们将数据库保存在/content/文件夹中。因此,每当我们使用这个配置连接到Chroma DB客户端时,Chroma DB将在提供的目录中查找现有的数据库并加载它。如果不存在,则会创建一个新的数据库。当我们关闭连接时,数据将保存到这个目录中。
现在,我们将创建一个集合。矢量存储中的集合是我们保存向量嵌入、文档以及任何可用的元数据的地方。在矢量数据库中,集合可以看作是关系数据库中的表。
创建集合并添加文档
我们将创建一个集合并向其中添加文档。
collection = client.create_collection("my_information")
collection.add(
documents=["This is a document containing car information",
"This is a document containing information about dogs",
"This document contains four wheeler catalogue"],
metadatas=[{"source": "Car Book"},{"source": "Dog Book"},{'source':'Vechile Info'}],
ids=["id1", "id2", "id3"]
)
矢量数据库
现在模型已经成功将我们的三个文档以向量嵌入的形式存储在向量存储中。现在,我们将查找与之相关的文档。我们将传递一个查询,并获取与之相关的文档。对应的代码如下:
results = collection.query(
query_texts=["Car"],
n_results=2
)
print(results)
更新和删除数据
collection.update(
ids=["id2"],
documents=["This is a document containing information about Cats"],
metadatas=[{"source": "Cat Book"}],
)
数据库查询
results = collection.query(
query_texts=["Felines"],
n_results=1
)
print(results)
煩惱功能
有一个类似于update(更新)函数的函数称为upsert(更新或插入)函数。update(更新)函数和upsert(更新或插入)函数的唯一区别是,如果在update(更新)函数中指定的文档ID不存在,update(更新)函数将会引发错误。但是在upsert(更新或插入)函数的情况下,如果集合中不存在指定的文档ID,则会将其添加到集合中,类似于add(添加)函数的操作。
有时候,为了减少空间或删除不必要的信息,我们可能希望从向量存储中删除一些文档,而保留HTML结构。
collection.delete(ids = ['id1'])
results = collection.query(
query_texts=["Car"],
n_results=2
)
print(results)
计数函数
collection.modify(name="new_collection_name")
修改功能
my_collection = client.get_collection(name="my_information_2")
client.delete_collection(name="my_information_2")
结论
ChromaDB是一个强大的工具,它允许我们以语义化的方式处理和搜索数据。它在使用转换模型创建嵌入时提供了灵活性,并提供了有效的方法来缩小搜索结果范围。无论您管理的是一小批文件还是一个大型数据库,ChromaDB的语义搜索功能可以帮助您快速准确地找到最相关的信息。
我希望您发现使用ChromaDB进行语义搜索的教程很有帮助。机器学习和自然语言处理的威力为信息检索开启了一个全新的可能性世界,而ChromaDB是您工具库中非常棒的一款工具。