情感分析与微调模型

什么是情感分析?
情感分析是一种自然语言处理技术,用于确定一系列词语、短语或句子的情感色彩。
近年来,情感分析在各个领域获得了广泛的应用,例如客户服务、品牌监测和社交媒体分析。
随着预训练语言模型(例如BERT - 双向编码器变换器表示)的出现,执行情感分析任务变得更加容易。
本文将探讨如何使用Hugging Face对经过预先训练的BERT模型进行情感分析的微调,并将其推向Hugging Face模型中心。
此项目的所有代码都可以在GitHub上找到。
为什么选择 Hugging Face?
拥抱脸是一个平台,提供了一套全面的自然语言处理(NLP)和机器学习任务工具和资源。
它提供了一个用户友好的界面以及多种预训练模型、数据集和库,可以供数据分析师、开发人员和研究人员使用。
Hugging Face 提供了大量预训练模型,这些模型在大型数据集上进行了训练,旨在执行特定的自然语言处理任务,例如文本分类、情感分析、命名实体识别和机器翻译。
这些模型为您的分析提供了一个起点,并为您节省了从头开始训练模型的时间和精力。
对于这个项目,我建议您学习关于自然语言处理(NLP)的所有知识,使用来自Hugging Face生态系统的库来学习。
请前往网站并登录,以访问平台的所有功能。
阅读更多关于使用Hugging Face进行文本分类的内容。
在Google Colab上使用GPU运行时。
在我们开始编码前,了解为什么在Google Colab上使用GPU运行时是有益的非常重要。
GPU代表图形处理单元,是专门设计处理复杂图形和计算任务的强大硬件。
拥抱脸模型采用深度学习技术,因此训练它们需要大量的计算机GPU计算能力。
请使用Colab来完成,或者使用其他GPU云供应商,或拥有NVIDIA GPU的本地机器。
在我们的项目中,我们利用谷歌Colab上的GPU运行时来加快训练过程。
要在Google Colab上访问GPU,我们只需要在创建新笔记本时选择GPU运行环境。
这使我们能够充分利用 GPU 的能力,并且更快地完成训练任务。
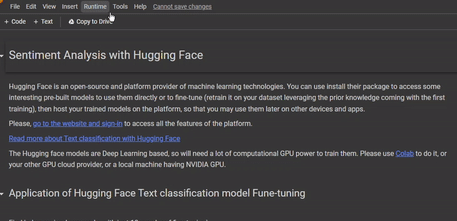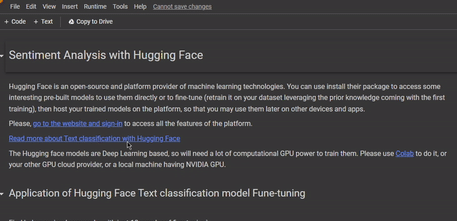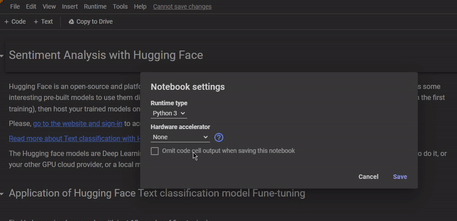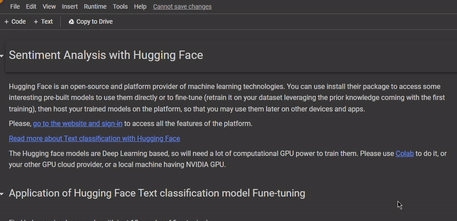
将运行时更改为GPU
设置
既然我们理解了GPU的重要性,让我们深入代码吧。我们首先安装变形器库,这是一种由Hugging Face开发的基于Python的库。
这个库为一组预训练模型及其微调工具提供支持。我们还会安装其他要求。
!pip install transformers
!pip install datasets
!pip install --upgrade accelerate
!pip install sentencepiece接下来,我们导入必要的库并加载数据集。在这个项目中,我们将使用来自Zindi Challenge的数据集,可以在此处下载。
import huggingface_hub # Importing the huggingface_hub library for model sharing and versioning
import numpy as np
import pandas as pd
from datasets import load_dataset
from sklearn.model_selection import train_test_split
from datasets import DatasetDict, Datasetfrom transformers import AutoModelForSequenceClassification
from transformers import TFAutoModelForSequenceClassification
from transformers import AutoTokenizer, AutoConfig
from transformers import TrainingArguments, Trainer, DataCollatorWithPadding# Load the dataset from a GitHub link
url = "https://raw.githubusercontent.com/ikoghoemmanuell/Sentiment-Analysis-with-Finetuned-Models/main/data/Train.csv"
df = pd.read_csv(url)# A way to eliminate rows containing NaN values
df = df[~df.isna().any(axis=1)]
加载数据集并删除NaN值后,我们通过拆分预处理数据来创建训练和验证集合。
我们还创建了一个PyTorch数据集。 PyTorch数据集提供了一种标准格式,对于我们的机器学习过程来说更加高效和便捷。
通过遵循这个数据集格式,我们可以确保数据处理的一致性,并无缝地集成其他PyTorch功能。
# Split the train data => {train, eval}
train, eval = train_test_split(df, test_size=0.2, random_state=42, stratify=df['label'])# Create a pytorch dataset # Create a train and eval datasets using the specified columns from the DataFrame
train_dataset = Dataset.from_pandas(train[['tweet_id', 'safe_text', 'label', 'agreement']])
eval_dataset = Dataset.from_pandas(eval[['tweet_id', 'safe_text', 'label', 'agreement']])
# Combine the train and eval datasets into a DatasetDict
dataset = DatasetDict({'train': train_dataset, 'eval': eval_dataset})
# Remove the '__index_level_0__' column from the dataset
dataset = dataset.remove_columns('__index_level_0__')
预处理
接下来,我们清洗文本数据并进行分词。机器学习模型只能理解数字。
分词对于创建文本的数字表示非常重要,通常被称为词嵌入。
词嵌入是一种密集向量表示形式,它捕捉单词之间的语义意义和关系。
这些表征使机器能够理解单词之间的上下文信息和相似之处,从而促进更高级的自然语言处理任务。
为预处理,我们将使用两个常用的文本预处理函数和标签转换函数。
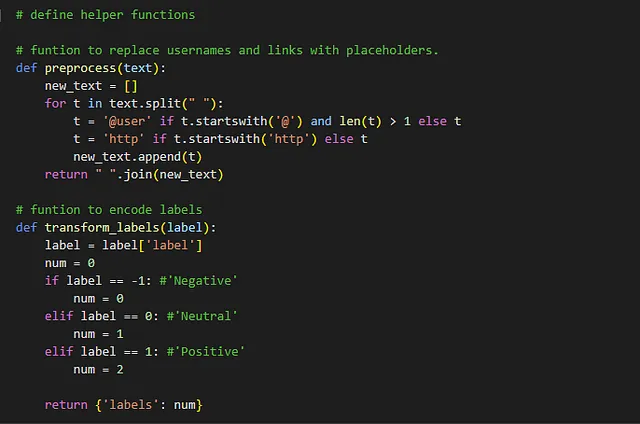
- 预处理函数通过将用户名和链接替换为占位符来修改文本。transform_labels函数将标签从字典格式转换为数字表示。
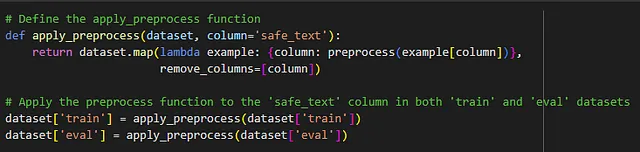
标记化
checkpoint = "cardiffnlp/twitter-xlm-roberta-base-sentiment"
# define the tokenizer
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_data(example):
return tokenizer(example['safe_text'], padding='max_length')
# Change the tweets to tokens that the models can exploit
dataset = dataset.map(tokenize_data, batched=True)
# Transform labels and remove the useless columns
remove_columns = ['tweet_id', 'label', 'safe_text', 'agreement']
dataset = dataset.map(transform_labels, remove_columns=remove_columns)- 我们定义一个检查点变量,它保存了我们想要使用的预训练模型的名称或标识符。在这种情况下,它是“cardiffnlp/twitter-xlm-roberta-base-sentiment”模型。
- tokenizer = AutoTokenizer.from_pretrained(checkpoint):我们使用transformers库中的AutoTokenizer类创建一个分词器对象。分词器负责将文本数据转换为数字标记,以便模型能理解。
- 保持HTML结构,将以下英文文本翻译为简体中文: def tokenize_data(example):我们定义一个名为tokenize_data的函数,该函数以数据集中的一个示例作为输入。该函数使用分词器对示例中的文本进行分词,并应用填充来确保所有输入具有相同的长度。
- dataset = dataset.map(tokenize_data, batched=True):我们使用map方法将tokenize_data函数应用于整个数据集。这将文本数据在‘safe_text’列中转化为tokenized representations,有效地为模型的消耗准备好了数据。batched=True参数表示应在批处理中应用映射操作以提高效率。
- remove_columns = [ 'tweet_id', 'label', 'safe_text', 'agreement' ]:我们创建了一个名为remove_columns的列表,其中包含我们想要从数据集中删除的列的名称。
- 数据集 = 数据集.map(转换标签, remove_columns=remove_columns):我们使用map方法对数据集应用另一种转换。这次,我们使用转换标签函数将数据集中的标签转换为数字值。另外,我们从数据集中删除指定的列,有效地将它们丢弃。
通过将文本数据进行标记化处理并删除不必要的列,同时转换标签,我们可以预处理数据集,以便使用情感分析模型进行训练或评估。
训练
现在我们已经有了预处理的数据,可以对预先训练的模型进行微调,用于情感分析。首先,我们将指定我们的训练参数。
# Configure the trianing parameters like `num_train_epochs`:
# the number of time the model will repeat the training loop over the dataset
training_args = TrainingArguments("test_trainer",
num_train_epochs=10,
load_best_model_at_end=True,
save_strategy='epoch',
evaluation_strategy='epoch',
logging_strategy='epoch',
logging_steps=100,
per_device_train_batch_size=16,
)我们设定了训练模型的超参数,例如epochs的数量,batch大小和学习率。
我们将加载预先训练的模型,对数据进行洗牌,然后定义评估指标。在这种情况下,我们使用rmse。
# Loading a pretrain model while specifying the number of labels in our dataset for fine-tuning
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=3)train_dataset = dataset['train'].shuffle(seed=24)
eval_dataset = dataset['eval'].shuffle(seed=24) def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {"rmse": mean_squared_error(labels, predictions, squared=False)}
我们可以通过使用提供的训练和评估数据集来轻松训练和评估我们的模型,方法是使用以下参数初始化Trainer对象。
Trainer 类处理训练循环、优化、日志记录和评估,使我们更容易专注于模型开发和分析。
trainer = Trainer(
model,
training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)最后,我们可以使用训练模型。
trainer.train()
并使用启动最终评估。
trainer.evaluate()
请看以下示例,只进行了10个时期的微调。
笔记本在nbviewer上
在此处阅读有关微调概念的更多信息。
下一步
想知道接下来该怎么做吗?例如,下一步就可以使用 Streamlit 或 Gradio 来部署您的模型。
这将是一个网页应用程序,您的用户可以与之交互以进行预测。这是两个使用刚刚调整的模型构建的网络应用程序的截图。
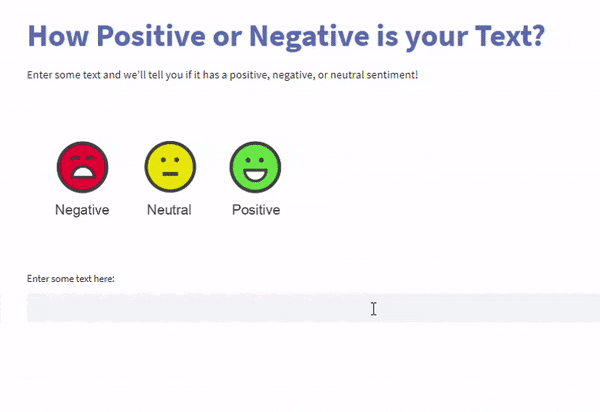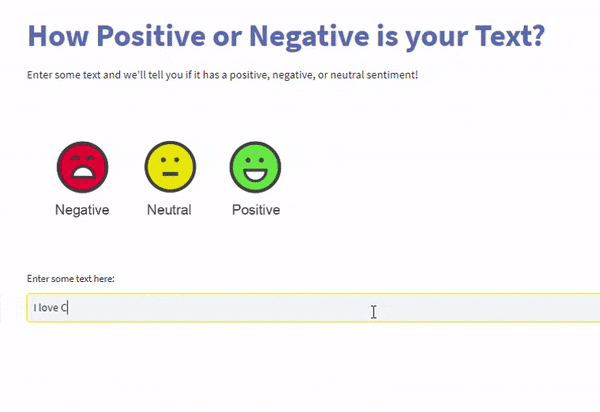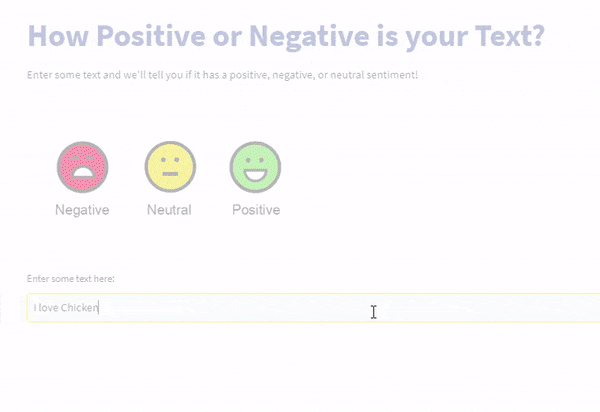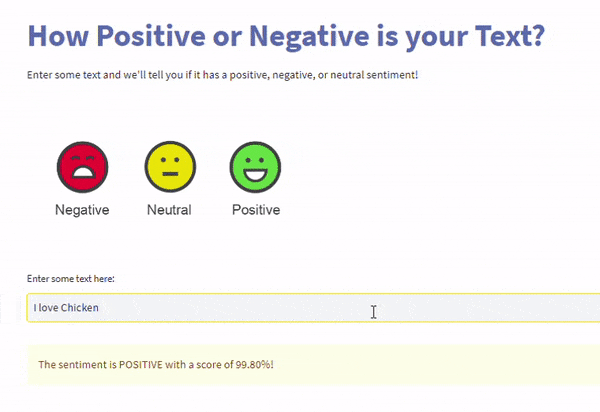
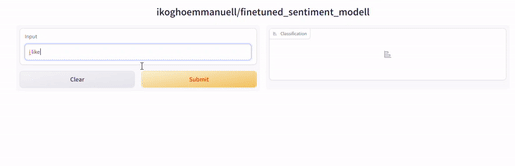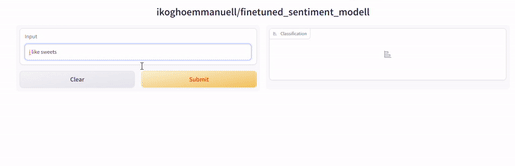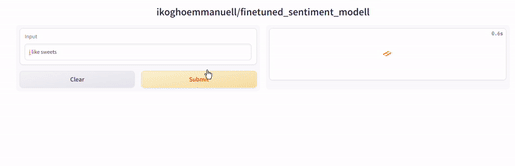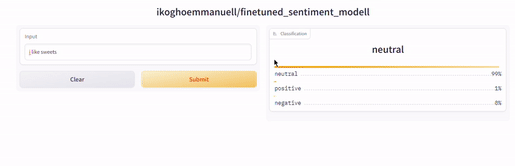
结论
总结
我们使用Hugging Face库fine-tuned了一个预训练的模型,用于情感分析的数据集。在进行了10个训练轮次后,该模型在验证集上实现了0.7的RMSE得分。
如果您发现了这篇文章很精彩,那么请在Learnhub博客上发表更多精彩的文章;我们写了很多从云计算到前端开发、网络安全、人工智能和区块链的技术相关主题。请查看如何构建离线网络应用程序。
Emmanuel Ikogho 写了这篇文章; Emmanuel 是一位数据科学家,目前正在和 Azubi Africa 培训以提升他的数据职业生涯。
资源
- 自然语言处理的简介
- 在15分钟内开始使用拥抱脸(Hugging Face)
- 调整神经网络的解释
- 优化DistilBert - Hugging Face变压器用于诗歌情感预测| NLP
- NLP 简介:播放列表





