通过我们的Chrome扩展程序——PageChat提升您的网页浏览体验。
看看我们是如何构建“PageChat”的,这是一个Chrome扩展程序,让用户能够访问ChatGPT并询问和总结网页的问题。

作为一个开发者,我一整天都在使用ChatGPT帮助我的工作,而且我常常发现我想在一个网页上读到的主题上问问题。因此,我决定编写一个Chrome扩展程序,让你可以这样做。这个扩展程序允许你从任何网页访问ChatGPT,以及提出关于你所在的页面的问题或总结它。扩展程序还记住你的聊天历史,所以你可以稍后继续你的对话。
在我深入探讨如何编写这个扩展程序之前,如果您不熟悉谷歌浏览器扩展程序的开发,我建议您阅读官方Chrome扩展程序文档中的架构概述。
技术栈
作为 React 粉丝,我决定使用它构建用户界面。我也喜欢 Vite 打包工具,因为它在开发过程中提供快速的重新加载,并且需要最少的配置。然而,我不能直接使用 Vite 模板来构建 Chrome 扩展程序。Chrome 扩展程序和典型的 React 应用程序之间的入口点存在差异。扩展程序的入口点是 manifest.json 文件,而不是 HTML 页面。这个文件包含扩展程序的元数据以及内容、后台脚本和弹出窗口以及选项页面的路径。幸运的是,我找到了一个名为 CRXJS 的 Vite 插件,专门解决这个问题。这个插件解析 manifest.json 文件并生成适当的 Vite 配置,确保 manifest.json 和其中引用的文件被编译并导出到输出目录 dist 中。这也意味着当我们开发 React 应用程序时,我们习惯使用的热模块替换(HMR)和静态资产导入等功能将按预期工作。
弹出窗口
弹出窗口组件是扩展的主要用户界面。当用户单击浏览器工具栏中的扩展图标时,便会看到它。它由src/popup.tsx脚本挂载到manifest.json中引用的popup.html页面上。
用户第一次打开弹出窗口时,将呈现“选项组件”,要求提供OpenAI API密钥。该密钥通过使用“useSettingStorage”自定义钩子存储在扩展程序的本地存储中,该自定义钩子在幕后使用“SettingsStoreContext”。
export default function Popup(){
const { loading, settings } = useSettingsStore();
/* ... */
if (loading || !settings.openAIApiKey) {
return <Options />;
}
/* ... */
}
export default function Options() {
const { loading, settings, setSettings } = useSettingsStore();
const [openAIApiKeyInputText, setOpenAIApiKeyInputText] = useState("");
/* ... */
const saveOptions = useCallback(
(event: FormEvent<HTMLFormElement>) => {
event.preventDefault();
try {
setSettings({
...settings,
openAIApiKey: openAIApiKeyInputText,
});
/* ... */
} catch (error) {
/* ... */
}
},
[openAIApiKeyInputText, setSettings, settings, /* ... */]
);
return (
<div>
<form onSubmit={saveOptions} >
{ /* ... */}
<button type="submit">
Save
</button>
</form>
</div>
);
}注:用户还可以通过右键单击扩展图标并从上下文菜单中选择“选项”来稍后更改API密钥。这将在Chrome扩展程序管理页面上打开选项组件,如下所示。
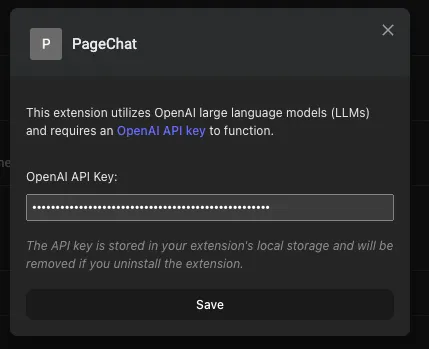
一旦设置好OpenAI API密钥,聊天机器人和网页摘要组件就会渲染成选项卡。
聊天机器人
聊天机器人组件是用户与ChatGPT进行交互的地方。它有两种模式:与GPT聊天和与页面聊天。第一种模式是默认模式,它允许用户直接与GPT聊天。第二种模式允许用户询问关于他们所在页面的问题。用户可以通过从组件顶部的下拉菜单中选择相应选项来在两种模式之间切换。
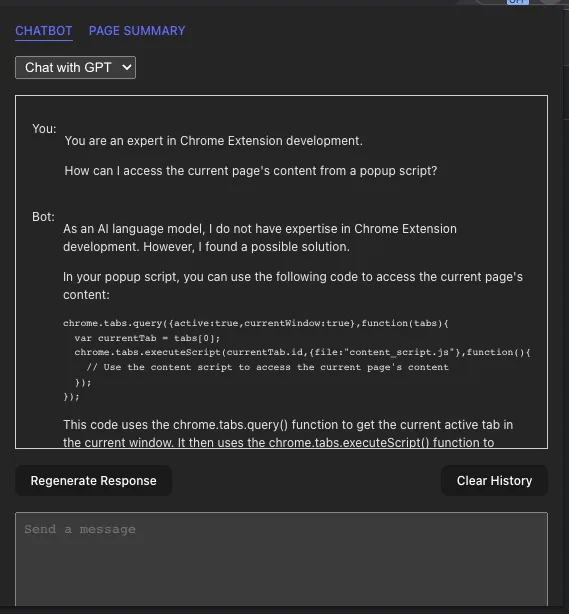
在任何模式下,我使用LangChain与OpenAI API进行接口交互。 LangChain是一个非常棒的库,可以让您与许多大型语言模型(LLM),包括OpenAI的GPT和嵌入模型进行接口交互。它还提供了许多工具,用于处理文本数据的预处理和后处理,在使用LLMs时必须进行这些操作。
GPT模式的聊天机器人
当Chatbot安装并且以Chatbot with GPT模式运行时,它会使用我编写的useChatHistory自定义钩子从本地存储加载存储的设置和现有聊天历史。
const { settings, setSettings } = useSettingsStore();
const { openAIApiKey, chatMode = "with-llm" } = settings;
const [, history, setHistory] = useChatHistory([], chatMode);在后台,useChatHistory使用通用的useStoredState钩子从本地存储加载和保存聊天历史记录。
然后,它将初始化一个ConversationChain实例,如下所示:
const chain = useMemo(() => {
const llm = new ChatOpenAI({
openAIApiKey: openAIApiKey,
// temperature: 0,
streaming: true,
verbose: true,
callbacks: [
{
handleLLMNewToken(token: string) {
setResponseStream((streamingText) => streamingText + token);
},
handleLLMEnd() {
setResponseStream("");
},
},
],
});
/* ... */
return new ConversationChain({
memory: new BufferMemory({
returnMessages: true,
inputKey: "input",
memoryKey: "history",
chatHistory: {
async getMessages() {
return history;
},
async addUserMessage(message) {
setHistory((history) => [...history, new HumanChatMessage(message)]);
},
async addAIChatMessage(message) {
setHistory((history) => [...history, new AIChatMessage(message)]);
},
async clear() {
setHistory([]);
},
},
}),
llm: llm,
prompt: ChatPromptTemplate.fromPromptMessages([
new MessagesPlaceholder("history"),
HumanMessagePromptTemplate.fromTemplate("{input}"),
]),
});
}, [openAIApiKey, chatMode, history, setHistory /* ... */]);ConversationChain是LangChain提供的一个类。在LangChain中,链是一个包装器,可以包装像LLM实例、内存或其他链之类的基元,以便您可以使用LLM和其他系统创建复杂的交互。这里,我们使用ConversationChain,因为它包装了一个LLM实例和内存,并确保我们对LLM的提示和响应被透明地存储在内存中。
该链配置的内存类型是BufferMemory,它允许您通过传递实现以下方法的对象来决定聊天历史记录的存储方式:
async getMessages() {}
async addUserMessage(message){}
async addAIChatMessage(message){}
async clear() {}我的实现只是将这些方法委托给使用 useChatHistory 钩子返回的访问器。
您还会注意到,提示模板有一个占位符新消息占位符("history"),该链将在调用时使用内存中存储的聊天历史记录替换它。这就是我们如何确保聊天历史记录包含在对LLM的提示中。
LLM实例是通过OpenAI API密钥和两个回调函数进行初始化的。第一个回调函数在LLM生成令牌并将其附加到responseStream状态时调用。第二个回调函数在LLM完成处理提示时调用。在这种情况下,我们清除responseStream状态。根据我的经验,如果没有这种流媒体功能,我可以访问到的LLMs感觉太慢,无法用作聊天机器人。
初始化的ConversationChain已经被缓存,除非它依赖的状态发生了变化,否则组件重新渲染时不需要重新初始化。
当用户输入消息并按下回车键时,会调用sendUserMessage处理程序:
const sendUserMessage = useCallback(
async (event: FormEvent<HTMLFormElement>) => {
/* ... */
try {
abortControllerRef.current = new AbortController();
setUserInputAwaitingResponse(userInput);
setUserInput("");
if (chain instanceof ConversationChain) {
const response = await chain.call({
input: userInput,
signal: abortControllerRef.current?.signal,
});
} else if (chain instanceof ConversationalRetrievalQAChain) {
/* ... */
}
} catch (error) {
/* ... */
} finally {
/* ... */
}
},
[chain, history, setHistory, userInput]
);在这里,我们使用用户输入来调用该链。在后台,该链将使用初始化时的提示模板构建提示,并调用LLM处理提示。LLM将开始将响应流式传输回handleLLMNewToken回调函数。当流式传输完成时,将调用handleLLMEnd回调函数。在链调用返回之前,用户消息和LLM响应会被透明地添加到聊天记录中。
以下是我向用户呈现聊天历史的方式,考虑了聊天机器人可能存在的不同状态:
function ChatMessageRow({ message }: { message: BaseChatMessage }) {
return (
<div>
<span>{message instanceof HumanChatMessage ? "You: " : "Bot: "}</span>
<div>
<ReactMarkdown children={message.text} />
</div>
</div>
);
}
function Chatbot{
/* ... */
return (
<div>
{/* ... */}
{(history.length > 0 ||
userInputAwaitingResponse ||
responseStream ||
error) && (
<div>
{history.map((message, index) => {
return <ChatMessageRow key={index} message={message} />;
})}
{userInputAwaitingResponse && (
<ChatMessageRow
message={new HumanChatMessage(userInputAwaitingResponse)}
/>
)}
{responseStream && (
<ChatMessageRow message={new AIChatMessage(responseStream)} />
)}
{error && (
<ChatMessageRow message={new AIChatMessage(`Error: ${error}`)} />
)}
</div>
)}
{/* ... */}
</div>
);
}顺便提一句,在这种模式下,聊天记录可以从任何页面访问,并在用户清除之前跨浏览器会话中保留。
页面聊天机器人
此模式旨在回答用户所在页面的问题。从概念上讲,我们可以通过将页面内容作为上下文包含在 LLM 的提示中来实现这一点,如下所示:
`Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:`这对于小页面来说是可以的,但LLM有一定的提示长度限制。对于ChatGPT-3.5-turbo,它的令牌限制为4,096个(1个令牌约为4个字符或3/4个英文单词)。GPT-4有不同的版本,最大令牌限制分别为8,192个和32,768个。为了避免这个限制,我们必须将页面内容分成块,并将相关块作为上下文添加到提示中。
一个适合上述任务的先进工具是向量存储器。向量存储器是一种数据库,它存储文档及其嵌入,以便基于与查询嵌入的相似性有效检索相关文档。
为了保持简单,我在useEffect回调中将页面内容加载到一个MemoryVectorStore实例中,具体如下:
async function getCurrentPageContent() {
const [tab] = await chrome.tabs.query({
active: true,
currentWindow: true,
});
if (!tab.id) return;
try {
return await chrome.tabs.sendMessage<
GetPageContentRequest,
GetPageContentResponse
>(tab.id, {
action: "getPageContent",
});
} catch (error) {
console.error(error);
throw new Error("Unable to get page content");
}
}
useEffect(() => {
let ignore = false;
async function loadPageIntoVectorStore() {
try {
const pageContent = await getCurrentPageContent();
if (!pageContent?.pageContent) return;
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 4000,
chunkOverlap: 200,
});
const docs = await textSplitter.createDocuments([
pageContent.pageContent,
]);
const vectorStore = await MemoryVectorStore.fromDocuments(
docs,
new OpenAIEmbeddings({ openAIApiKey })
);
if (ignore) return;
setPageContentVectorStore(vectorStore);
} catch (error) {
console.error(error);
setError(`Error: ${error}`);
}
}
if (chatMode === "with-page") {
loadPageIntoVectorStore();
}
return () => {
ignore = true;
};
}, [chatMode, openAIApiKey]);在上面的代码片段中有很多内容,让我们一步一步来理解。
为了获取页面内容,我首先查询Chrome获取有关当前选项卡的信息。然后,我向我编写的插入到当前选项卡的扩展名中的内容脚本发送一个异步消息,有效负载为{action:“getPageContent”}。内容脚本是扩展名的唯一组成部分,可以访问当前页面的DOM,也称为主机页面。其他需要有关DOM的信息的扩展组件(例如弹出窗口和后台脚本)必须发送消息到内容脚本才能获取它。
如下所示,内容脚本响应页面主要内容元素的innerText:
chrome.runtime.onMessage.addListener(function (
request: GetPageContentRequest,
_sender,
sendResponse
) {
if (request.action === "getPageContent") {
const primaryContentElement =
document.body.querySelector("article") ??
document.body.querySelector("main") ??
document.body;
sendResponse({
pageContent: primaryContentElement.innerText,
} as GetPageContentResponse);
}
});我接着使用RecursiveCharacterTextSplitter将页面内容划分为每个片段 4,000 个字符(大约 1000 个标记)长,这些片段之间有 200 个字符的重叠。
最后,我使用这些块和一个OpenAIEmbeddings模型实例来初始化MemoryVectorStore,以便它可以为每个块生成嵌入。初始化后的向量存储保存在状态变量中。
接下来,我将按如下方式初始化一个ConversationalRetrievalQAChain实例:
if (chatMode === "with-page") {
if (!pageContentVectorStore) return undefined;
return ConversationalRetrievalQAChain.fromLLM(
llm,
pageContentVectorStore.asRetriever()
);
}ConversationalRetrievalQAChain是由LangChain提供的另一条链接,旨在根据问题从向量存储库中检索相关文档块,并将它们包括在LLM的提示中。此外,正如我们后面将看到的那样,它支持聊天记录,以便用户可以提出后续问题。
类似于我们之前看到的ConversationChain,初始化的ConversationalRetrievalQAChain被记忆化了,当组件重新渲染时不需要重新初始化。
当用户输入页面相关问题并按下回车键时,将调用sendUserMessage处理程序:
const sendUserMessage = useCallback(
async (event: FormEvent<HTMLFormElement>) => {
/* ... */
try {
abortControllerRef.current = new AbortController();
setUserInputAwaitingResponse(userInput);
setUserInput("");
if (chain instanceof ConversationChain) {
/* ... */
} else if (chain instanceof ConversationalRetrievalQAChain) {
const response = await chain.call({
question: userInput,
chat_history: history.map((message) => message.text),
signal: abortControllerRef.current?.signal,
});
setHistory((history) => [
...history,
new HumanChatMessage(userInput),
new AIChatMessage(response.text),
]);
} catch (error) {
/* ... */
} finally {
/* ... */
},
[chain, history, setHistory, userInput]
);这一次,我使用用户输入调用ConversationalRetrievalQAChain。我还必须手动传递聊天历史记录,因为该链没有记忆组件。 LLM返回响应的方式与之前相同,但是当调用结束时,用户信息和LLM响应将被手动添加到聊天历史记录中。
在内部,如果存在聊天记录,ConversationalRetrievalQAChain会将回答问题的任务分为两个步骤。首先,它将向LLM发送以下提示,要求它重新表述用户的问题,以考虑聊天历史记录。
`Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:`然后,它使用新问题从其向量存储库中检索相关块,并向LLM发送以下提示以回答问题。
`Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:`以下关于消息传递页面的扩展文档聊天,说明了如何运作:
第一个问题:这个页面是关于什么的?
第一个回应:此页面是关于Chrome扩展中的消息传递,包括使用一次性请求和长期连接在内容脚本和扩展的其他部分之间进行通信,跨扩展消息传递以及网页和扩展之间的消息传递。它还涵盖了安全考虑因素和避免跨站脚本和验证输入的最佳实践。最后,它包括有关如何使用本机消息传递功能将消息发送到本机应用程序的信息。
第二个问题:我如何确保安全?
改述问题:在Chrome扩展中避免跨站脚本和验证输入的最佳安全考虑和最佳实践是什么?
第二个响应:为了避免跨站脚本和验证Chrome扩展程序中的输入,开发人员应该注意内容脚本的安全考虑,内容脚本比扩展服务工作人员不太可信。内容脚本的消息可能是由攻击者制作的,因此所有输入都应该进行验证和消毒。此外,应避免危险的API(如eval()和innerHTML),而应使用更安全的API,如JSON.parse()和innerText。最佳做法还包括使用承诺而不是回调,使用持久连接进行超过单个请求和响应的对话,并设置适当的端口生命周期管理。此外,开发人员可以在其manifest.json中使用externally_connectable来指定要与之通信的网站,并通过runtime.onMessageExternal或runtime.onConnectExternal API接收并监听来自Web页面的消息。
页面总结
页面摘要是使用LLMs解决的有趣任务,鉴于它们可以处理的提示长度的限制。虽然对于问答任务,我们可以通过使用向量库来绕过此约束,但是摘要要求LLM处理整个文档。值得庆幸的是,LangChain有一个MapReduceDocumentsChain可用于处理这些问题。
当用户切换到“页面概述”选项卡时,将加载PageSummary组件,并使用useStoredState钩子从会话存储中加载先前生成的摘要。
const [loading, summary, setSummary] = useStoredState<StoredSummary>({
storageKey: StorageKeys.PAGE_SUMMARY,
defaultValue: INITIAL_SUMMARY,
storageArea: 'session',
scope: 'page'
});如果先前没有生成摘要,我会初始化一个摘要链实例,并按如下方式将页面内容作为块调用它:
useEffect(() => {
/* ... */
async function summarizeCurrentPage() {
if (loading || summary.content) return;
/* ... */
try {
const pageContent = await getCurrentPageContent();
if (!pageContent) return;
const llm = new ChatOpenAI({
openAIApiKey: openAIApiKey,
});
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 4000,
});
const docs = await textSplitter.createDocuments([
pageContent.pageContent,
]);
const template = SUPPORTED_SUMMARY_TYPES.find(
(type) => type.type === summary.type
)?.template;
if (!template) return;
const prompt = new PromptTemplate({
template: template,
inputVariables: ["text"],
});
const chain = loadSummarizationChain(llm, {
type: "map_reduce",
combineMapPrompt: prompt,
combinePrompt: prompt,
});
const response = await chain.call({
input_documents: docs,
});
/* ... */
setSummary({
...summary,
content: response.text,
});
} catch (error) {
/* ... */
} finally {
/* ... */
}
}
summarizeCurrentPage();
/* ... */
}, [loading, openAIApiKey, setSummary, summary]);loadSummarizationChain只是一个辅助函数,当其类型参数为map_reduce时,返回一个已配置了摘要提示的MapReduceDocumentsChain实例:
export const loadSummarizationChain = (llm, params = { type: "map_reduce" }) => {
/* ... */
if (params.type === "map_reduce") {
const { combineMapPrompt = DEFAULT_PROMPT, combinePrompt = DEFAULT_PROMPT, returnIntermediateSteps, } = params;
const llmChain = new LLMChain({ prompt: combineMapPrompt, llm, verbose });
const combineLLMChain = new LLMChain({
prompt: combinePrompt,
llm,
verbose,
});
const combineDocumentChain = new StuffDocumentsChain({
llmChain: combineLLMChain,
documentVariableName: "text",
verbose,
});
const chain = new MapReduceDocumentsChain({
llmChain,
combineDocumentChain,
documentVariableName: "text",
returnIntermediateSteps,
verbose,
});
return chain;
}
/* ... */
};这个链条的工作方式是将文档中的每个块分别进行总结,然后将这些摘要组合成单个输入,再将其馈送给LLM以生成最终摘要。如果组合摘要过长,LLM无法处理,则将其分成块,并重复该过程,直到组合摘要+指令长度低于LLM的最大令牌限制。
该链还允许您为单个块(映射阶段)和组合摘要(减少阶段)提供不同的提示。我选择在两个阶段都使用相同的提示,但根据用户选择的摘要类型而有所不同。对于默认的摘要类型 Concise,将使用以下提示:
`Write a concise summary of the following in markdown format:
"{text}"
CONCISE SUMMARY:`以下是涵盖内容脚本深度的页面生成的示例摘要:
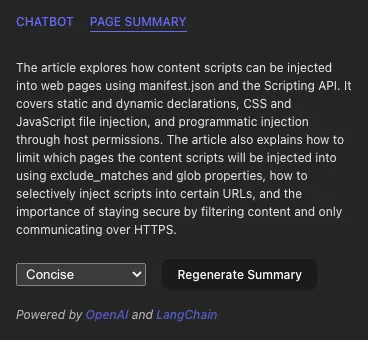

MapReduceDocumentsChain试图通过并行执行块的汇总来提高效率。然而,由于减少阶段的递归性质,它确保了联合汇总足够短,因此在处理大页面时可能会变慢。
结论
一些可以提升这个扩展的亮点改进:
- 聊天GPT的历史记录目前存储在本地存储中,最大为5MB。可以添加选项,允许用户将此责任转移至云存储,如Firebase或S3。这也可以使存储聊天与页面历史记录成为可能。
- 它可以支持保留多个聊天记录,并允许在它们之间切换 - 类似于ChatGPT网站的方式。
- 它可以同时支持与多个LLM聊天。这可能是该扩展的杀手功能。
- 它还可通过LangChain的工具抽象支持ChatGPT插件。
- 页面摘要目前在大页面上速度较慢,如果用户关闭弹出窗口或切换到另一个标签,可能会被取消。可以使用Service Worker在后台运行摘要,存储结果并在完成后向弹出窗口发送消息。
我希望本文对你们学习如何使用React和Vite开发Chrome扩展程序有所帮助。我也希望它能启发你们如何使用LangChain与LLMs进行接口操作来完成复杂任务。在我看来,这个领域的可能性是无限的。我鼓励你们尝试使用像LangChain这样的库,感受一下它所能实现的功能。
您可以在 Github 上找到此扩展的源代码。
关于任务数据
我们是设计师、工程师和战略家,致力于构建创新数字产品,改变公司的业务方式。了解更多:https://www.missiondata.com。