使用蜘蛛来提取动态和静态数据:从哪里开始提取数据
你想学习如何制作一个能够从静态或动态网站上爬取数据的爬虫吗?是的,你可以学会它,你需要耐心和持续的工作,即使你害怕蜘蛛,你也会喜欢爬虫。

网站类型:
有两种类型的网站,你主要从中提取数据。
- 动态
- 静态
静态网站相对容易提取数据,因为它保持了其结构,并且大部分包含HTML和CSS标签。您的第一个任务是观察网站的结构,然后可以进一步进行。您在如何查看网站的HTML和CSS方面感到困难,它其实很简单。
- 只需前往该网站,然后右键点击选择打开检查选项。
- 然后您可以看到一个侧边栏,其中包含该网站使用的所有标签。
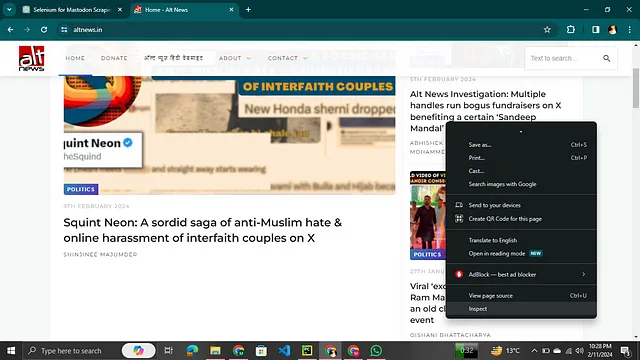
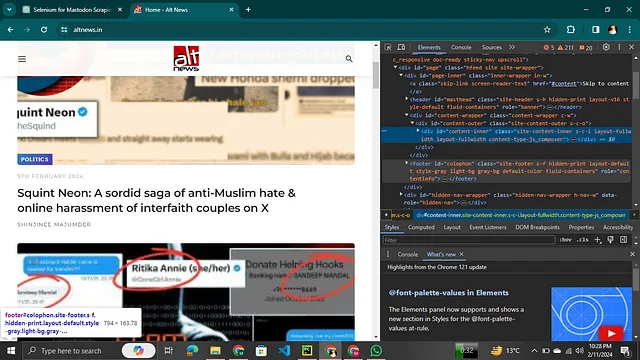
现在您可以很轻松地看到它的HTML和CSS!
现在真正要开始的是制作抓取器。
静态网站的爬虫
要求:
- 您需要在您的电脑上下载Python和PyCharm,您可以从此链接下载。(https://www.jetbrains.com/pycharm/download/?section=windows)
- 确保已在您的计算机上下载了Python,并在下载时添加路径。否则,您可能会遇到一些问题。
- 现在,你已经下载了Python和Pycharm,现在是时候设置你的Pycharm来进行网络爬虫了。
- 对于像Politifact这样的静态网站,您可以使用Scrapy和BeautifulSoup,这些都是Python的库。您可以通过使用命令进行安装。
pip install Scrapy
pip install beautifulsoup4
5. 在PyCharm上完成项目设置后,您可以在侧边栏上找到多个选项。
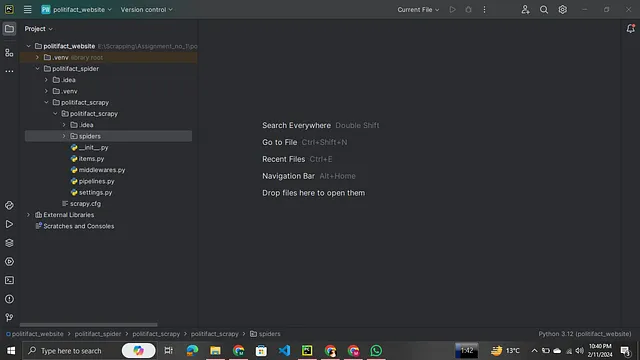
6. 现在您需要在蜘蛛文件夹中创建一个Python文件,名称由您自己确定,并以.py为后缀。
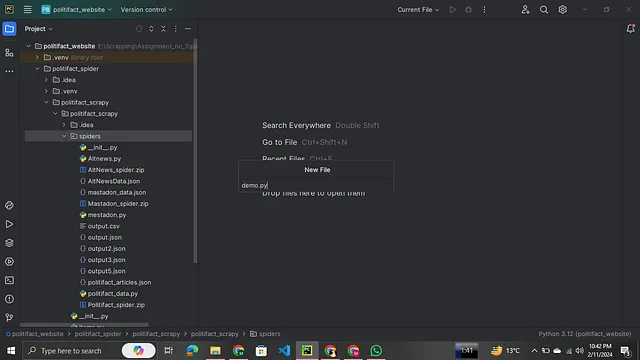
现在您可以看到已创建了demo.py文件,现在我们要开始编码部分了。
7. 在深入探索编码的复杂部分之前,我建议您访问链接https://scrapy.org/,以便对网络爬虫有基本的了解。该链接还提供了一个简单项目的演示,作为初学者,这对您会非常有益。
8. 我期望你已经访问了链接,现在对数据爬虫有了基本的了解,所以让我们来举一个稍微复杂的静态网站例子,并为其创建一个爬虫工具。
9. 我要抓取的网站是Politifact.com。
从现在开始,我将只重复我上面提到的步骤。请记住,我已经完成了项目,并根据此设置了我的PyCharm,并且已经进入了编码阶段,但我个人喜欢的做法是,在你进行数据抓取时,它需要引用CSS选择器或其他形式,但我喜欢使用XPath方法,我认为它易于使用,但无论如何选择哪种方法都是正确的。在这个例子中,我使用了CSS选择器。
首先,我分析了网站的结构,它是由一些复杂的HTML组成,但以下是其代码,您可以查看。不过我建议您先自己尝试,然后再查看我的代码。
import scrapy
from bs4 import BeautifulSoup
我已经使用Scrapy和BeautifulSoup了,就像我告诉过你的,对于静态网站,我们可以使用这些工具。我导入它们,然后使用它们。
class PolitifactSpider(scrapy.Spider):
name = 'politifact'
start_urls = ['https://www.politifact.com/article/list/?page={}'.format(page) for page in range(1, 11)]
def parse(self, response):
soup = BeautifulSoup(response.text, 'html.parser')
articles = soup.find_all("div", class_="m-teaser")
article_links = ["https://www.politifact.com" + article.find("h3", class_="m-teaser__title").find("a")["href"] for article in articles]
for link in article_links:
yield scrapy.Request(url=link, callback=self.parse_article)
def parse_article(self, response):
article = {}
# Extract relevant details using Scrapy selectors
article["title"] = response.css("div.m-statement__quote::text").get().strip()
# Extract and join the content into a string
article["content"] = ' '.join(response.css("article.m-textblock *::text").getall()).strip()
# Extract and join the images into a list
article["images"] = response.css("article.m-textblock img::attr(src)").getall()
# Extract author details
authors = []
for author in response.css("div.m-author"):
a = {}
if author.css("img"):
a["avatar"] = author.css("img::attr(src)").get()
a["name"] = author.css("div.m-author__content.copy-xs.u-color--chateau a::text").get().strip()
a["profile"] = "https://www.politifact.com" + author.css("div.m-author__content.copy-xs.u-color--chateau a::attr(href)").get()
authors.append(a)
article["authors"] = authors
yield article
以下是你一直在等待阅读的东西。现在要运行这段代码,你需要在终端中运行一个命令,但等等,你漏掉了一些重要的东西!猜猜看,是的,你漏掉了移动到要运行的文件!为此,你可以使用
cd name_of_folder
cd next_file
cd spiders
cd your_spider
在移动到您所需的文件后,您将在终端中看到如下内容。
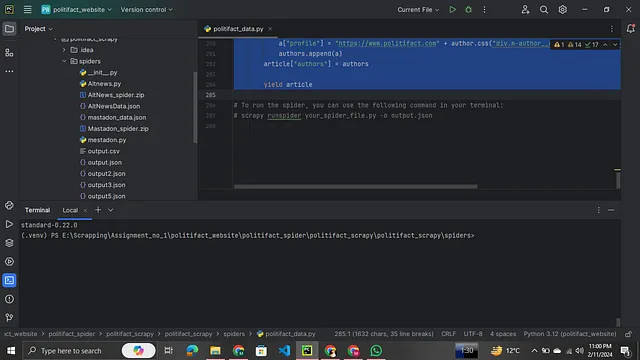
您可以看到我的命令已经经过了多么漫长的路径来到达我想要的位置,是的这是一段长途旅程。现在执行命令。
scrapy crawl your_spider_name
运行这个命令后,您可以获取到您的数据,但是有一件事情,如果您想将数据存储成JSON格式,您可以在命令中使用“-o 文件名.json”或者“csv”选项。以JSON格式,您可以看到结果如下:
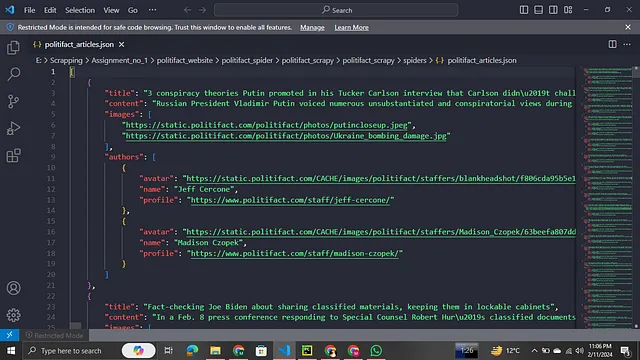
输出是Webby,你觉得怎么样?
动态网站
这种类型的网站不太容易提取数据。为此,我们使用Selenium来爬取数据,它不同于Scrapy,专门用于动态网站,特别是像Twitter和Mastodon这样的无限滚动网站。
您可以在网站https://selenium-python.readthedocs.io/上找到一些关于Selenium的阅读材料。
在开始之前,请访问此链接,并且您可以使用GPT或拥抱面容等LLM工具来获取帮助。
有两个网站我打算使用Selenium进行爬取,这两个网站都是动态的。第一个是https://www.altnews.in/,第二个是https://mastodon.social/explore。
我会给你代码,但请先尝试自己完成,这样能增加你的学习经验。你可以找到多种实现相同功能的选项,但如果你只是复制粘贴,你的学习就会受限。所以,让我们继续并首先爬取 altnews。
Altnews爬虫:
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
import asyncio
import json
json_file_path = r'E:\Scrapping\Assignment_no_1\politifact_website\politifact_spider\politifact_scrapy\politifact_scrapy\spiders\AltNewsData.json'
async def extract_data(driver):
# Scroll to the bottom
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Give some time for the new content to load
await asyncio.sleep(5) # Adjust this delay if needed
# Extract images
image_elements = driver.find_elements(By.XPATH, '//div[@class= "thumb-w"]//img')
image_urls = [img.get_attribute('src') for img in image_elements]
# Extract text links
text_link_elements = driver.find_elements(By.XPATH, '//h4[@class="entry-title pbs_e-t xs__h6 sm__h5"]//a')
text_link_data = [element.get_attribute('href') for element in text_link_elements]
# Extract author links
author_link_elements = driver.find_elements(By.XPATH, '//span[@class="author vcard"]//a')
author_text_data = [element.get_attribute('href') for element in author_link_elements]
# Extract news types
news_type_elements = driver.find_elements(By.XPATH, '//span[@class="author vcard"]//a')
news_type_data = [element.get_attribute('href') for element in news_type_elements]
# # Extract videos
# video_elements = driver.find_elements(By.XPATH, '//div[@class="video-player"]//video')
# video_urls = [video.get_attribute('src') for video in video_elements]
# Print or process the extracted data
print("Image URLs:", image_urls)
print("Text Link Data:", text_link_data)
print("Author Link Data:", author_text_data)
print("News Type Data:", news_type_data)
# print("Video URLs:", video_urls)
# Create a dictionary to store the extracted data
extracted_data = {
"Image URLs": image_urls,
"Text Link Data": text_link_data,
"Author Link Data": text_link_data,
"News Type Data": text_link_data,
# "Video URLs": video_urls
}
return extracted_data
async def main():
# Create a new instance of the browser
driver = webdriver.Chrome()
# Navigate to the Mastodon page
url = 'https://www.altnews.in/'
driver.get(url)
# Set the maximum number of scrolls
max_scrolls = 20
# List to store results from each iteration
results = []
# Outer loop for scrolls
for scroll_count in range(max_scrolls):
# Scroll to the bottom
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Run data extraction in parallel to scrolling
extracted_data = await asyncio.gather(extract_data(driver), asyncio.sleep(7)) # Adjust this delay if needed
results.append(extracted_data)
# Close the browser
driver.quit()
# Save results to a JSON file
with open(json_file_path, 'w') as json_file:
json.dump(results, json_file, indent=3)
# Run the event loop
asyncio.run(main())
简要说明如何从动态网站中提取数据,这并不是那么简单的任务。您可以从网站https://chromedriver.chromium.org/downloads单独下载Chrome驱动程序,并在进入setting.py选项后使用它,根据说明进行修改等等。在这种方法中一个重要的事项是您应该选择与您的Chrome版本相匹配的驱动程序版本,否则它将无法工作。如果您找不到确切的版本,您可以选择接近的版本,可能会起作用。
您可以通过在Chrome的右上角点击垂直点,然后选择"帮助"并点击"关于Google Chrome"来检查您的Chrome版本。您可以在那里看到您的Chrome版本。
在我的情况下,我使用seleniumwire,因为如果使用它,我不需要下载chrome driver,它也是一个Python库,可以处理这些事情,其余的代码在上面。
输出:
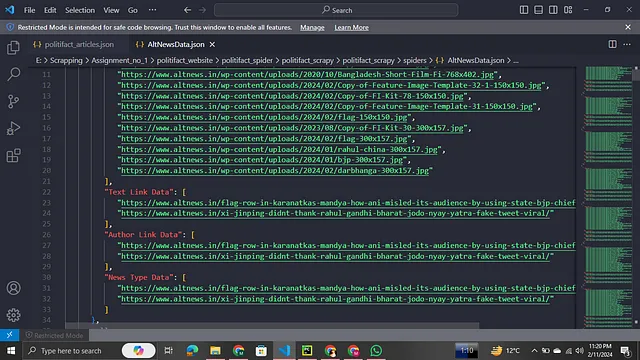
猛犸象爬虫:
与AltNews Scraper mastadon的爬虫代码相似
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
import asyncio
import json
json_file_path = r'E:\Scrapping\Assignment_no_1\politifact_website\politifact_spider\politifact_scrapy\politifact_scrapy\spiders\mastadon_data.json'
async def extract_data(driver):
# Scroll to the bottom
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Give some time for the new content to load
await asyncio.sleep(5) # Adjust this delay if needed
# Extract images
image_elements = driver.find_elements(By.XPATH,
'//div[@class="media-gallery__item standalone media-gallery__item--tall media-gallery__item--wide"]/a[@class="media-gallery__item-thumbnail"]//img')
image_urls = [img.get_attribute('src') for img in image_elements]
# Extract text
text_elements = driver.find_elements(By.XPATH,
'//div[@class="status__content__text status__content__text--visible translate"]/p')
text_data = [element.text for element in text_elements]
# Extract videos
video_elements = driver.find_elements(By.XPATH, '//div[@class="video-player"]//video')
video_urls = [video.get_attribute('src') for video in video_elements]
# Print or process the extracted data
print("Image URLs:", image_urls)
print("Text Data:", text_data)
print("Video URLs:", video_urls)
# Create a dictionary to store the extracted data
extracted_data = {
"Image URLs": image_urls,
"Text Data": text_data,
"Video URLs": video_urls
}
return extracted_data
async def main():
# Create a new instance of the browser
driver = webdriver.Chrome()
# Navigate to the Mastodon page
url = 'https://mastodon.social/explore'
driver.get(url)
# Set the maximum number of scrolls
max_scrolls = 20
# List to store results from each iteration
results = []
# Outer loop for scrolls
for scroll_count in range(max_scrolls):
# Scroll to the bottom
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Run data extraction in parallel to scrolling
extracted_data = await asyncio.gather(extract_data(driver), asyncio.sleep(7)) # Adjust this delay if needed
results.append(extracted_data)
# Close the browser
driver.quit()
# Save results to a JSON file
with open(json_file_path, 'w') as json_file:
json.dump(results, json_file, indent=3)
# Run the event loop
asyncio.run(main())
输出:
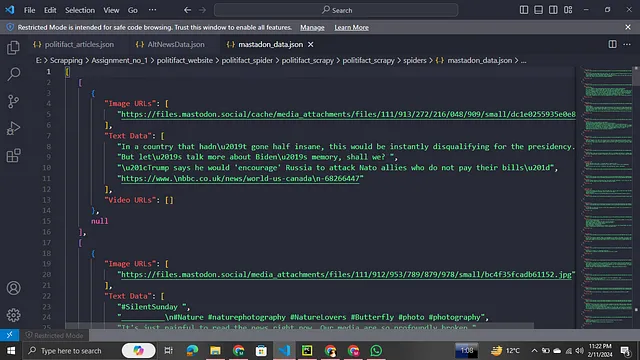
最后但同样重要的一点是你不需要运行命令。
scrapy crawl spider_name
在这种情况下,您必须直接运行它,因为我们正在使用Selenium。